Blog
Processing multiple aggregates - transactional vs eventual consistency

Introduction
When we use Domain Driven Design approach in our application, sometimes we have to invoke some method on multiple instances of aggregate of the same type.
For example, in our domain we have customers and when big Black Friday campaign starts we have to recalculate theirs discounts. So in domain model exists Customer aggregate with RecalculateDiscount method and in Application Layer we have DiscountAppService which is responsible for this use case.
There are 2 ways to implement this and similar scenarios.
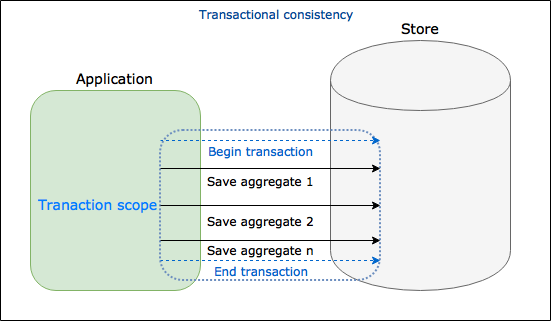
1. Using transactional consistency
// DiscountAppService - transaction consistency
public class DiscountAppService
{
private readonly ICustomersRepository customersRepository;
public DiscountAppService(ICustomersRepository customersRepository)
{
this.customersRepository = customersRepository;
}
public void RecalculateCustomersDiscounts()
{
var allCustomers = this.customersRepository.GetAll();
using(var transaction = new TransactionScope())
{
foreach(customer in allCustomers)
{
customer.RecalculateDiscount();
// Save changes to DB
}
transaction.Complete();
}
}
}This is the simplest solution, we get all customers aggregates and on every instance the RecalculateDiscount method is invoked. We surrounded our processing with TransactionScope so after that we can be certain that every customer have recalculated discount or none of them. This is transactional consistency - it provides us ACID and sometimes is enough solution, but in many cases (especially while processing multiple aggregates in DDD terms) this solution is very bad approach.
First of all, customers are loaded to memory and we can have performance issue. Of course we can change implementation a little, get only customers identifiers and in foreach loop load customers one by one. But we have worse problem - our transaction holds locks on our aggregates until end of processing and other processes have to wait. For the record - default transaction scope isolation level is Serializable. We can change isolation level but we can’t get rid of locks. In this case application becomes less responsive, we can have timeouts and deadlocks - things we should avoid how we can.
Processing commands with MediatR and Hanfire
2. Using eventual consistency
In this approach we do not use big transaction. Instead of this, we process every customer aggregate separately. Eventual consistency means that in specified time our system wile be in inconsistent state, but after given time will be consistent. In our example there is a time, that some of customers have discounts recalculated and some of them not. Let’s see the code:
public class DiscountAppService
{
private readonly ICustomersRepository customersRepository;
public DiscountAppService(ICustomersRepository customersRepository)
{
this.customersRepository = customersRepository;
}
public void RecalculateCustomersDiscounts()
{
var allCustomersIds = this.customersRepository.GetAllCustomerIds();
foreach (customerId in allCustomersIds)
{
Process(new RecalculateCustomerDiscountCommand(customerId));
}
}
private void Process(RecalculateCustomerDiscountCommand command)
{
// Execute processing asynchronously, for example:
// Using new Task.Run()
// Set background job in Hangfire/Quartz..etc
// Send message to Queue/Bus
}
}In this case on the beginning we got only customers identifiers and we process customer aggregates one by one asynchronously (and parallel if applicable). We removed problem of locking our aggregates for a long time. The simplest solution is usage of Task.Run() , but using this approach we totally losing control of processing. Better solution is to use some 3rd party library like Hangfire, Quartz.NET or messaging system.
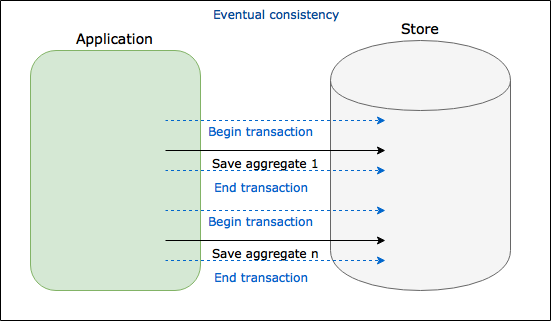
Eventual Consistency
Eventual consistency is a big topic used in distributed computing, encountered together with CQRS. In this article I would like to show only another way of executing batch processing using this approach and its benefits. Sometimes this approach is not a good choice - it can have impact on GUI and users may see stale data for some time. That is why it is important to talk with domain experts because often it is fine for user to wait for update of data but sometimes it is unacceptable.
Summary
Transactional consistency - whole processing is executed in one transaction. It is “all or nothing” approach and sometimes can lead to decrease performance, scalability and availability of our application.
Eventual consistency - processing is divided and not executed in one big transaction. In some time application will be in inconsistent state. It leads to better scalability and availability of application. On the other hand can cause problems with GUI (stale data) and it requires supporting mechanisms which enable parallel processing, retries and sometimes process monitors as well.
Image credits: upklyak on Freepik.
Comments
Related posts See all blog posts


