Blog
Database change management

Introduction
Database change management is not an easy task. It is even more difficult when we are at the beginning of a project where the data model is constantly changing. More people in the team is another difficulty because we have to coordinate our work and not interfere with each other. Of course, we can delegate database change management to one person, but this results in a bottleneck. In addition, we should take care of the deployment automation, because without automation we can not have truly continuous integration and delivery.
In this post I will describe:
- what we need to do to have a good database change management mechanism
- two common approaches to solve this problem
- recommendation, which approach should be taken
The ideal solution
I think we should stick to the same rules as when managing code changes. Which means that we should implement the following practices:
Everything should be in the source control
We should follow what was the change, who did it and when. There is no better tool for this than source control. Every little change, every little script should be thrown into the repository.
Every developer should be able to run migrations
Every developer should have local database on his own environment and should be able to always upgrade his database after downloading the changes. Without it, developer will have new version of application and old version of database. This will cause unpredictable behavior. Shared development databases say no! What is also important, the deployment of changes should be very fast.
Easy conflict resolution
Conflicts on the same database objects should be easy to solve and should not require a lot of work.
Versioning
We always should know in what version our database is. In addition, we should know what migrations have already been deployed and which ones not.
Deployment automation
Our mechanism should provide us with the ability to automate the deployment of changes to tests and productions environments. We should use the same mechanism during development to make sure everything will be fine and will work as expected.
The possibility of manual deployment
Sometimes changes can only be deployed manually by human due to procedures or regulations in the company. For this reason, we should be able to generate a set of scripts for manual deployment.
The ability to run “pre” and “post” deployment scripts
It is common to execute some logic before or/and after deployment. Sometimes we need regenerate some data, sometimes we need to check something (constraints integrity for example). This type of feature is very useful.
IDE support
It would be perfect to have the full support of our IDE. Quick access to objects schema (without connection to database), prompts, compile-time checking - these are the things we need to be very productive during database development.
A lot of these requirements, let’s see what solutions we have.
Versioning the State
The first approach to database change management is state versioning. We hold whole database definition in our source control repository and when we need change something we change objects definitions. When the upgrade time comes, our tool compares our actual definitions with target database and generates migration script for us (and he can execute it right away). The process looks as follows:
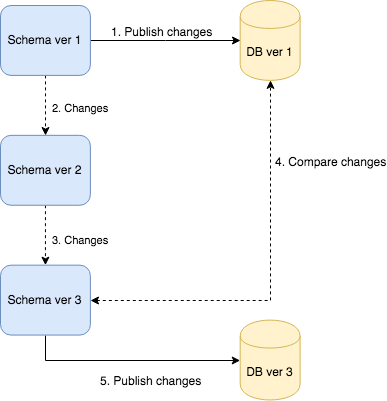
As I described we only change objects definitions. For example we have orders table and in our repository we have:
-- Orders table definition 1
CREATE TABLE [orders].[Orders]
(
[Id] INT NOT NULL PRIMARY KEY,
[Name] VARCHAR(50) NOT NULL
)When we need change something we just change definition:
CREATE TABLE [orders].[Orders]
(
[Id] INT NOT NULL PRIMARY KEY,
[Name] VARCHAR(70) NOT NULL,
[Description] VARCHAR(200) NULL
)I altered Name column and added Description column. That’s all - I changed state of my schema. The transition to this state is on the tool side.
Pros
- Compile-time checks (whole schema in one place)
- Ease of development
- History of definition of all objects
- Quick access to schema definition
- Ease of resolving conflicts
- IDE support
Cons
The biggest downside of this approach is that sometimes tool you are using can not be able to generate migration script based on differences. This is situation when you:
- try to add new not nullable column without default value.
- you have different order of columns in project vs target database. Then tool tries to change this order by creating temp tables, coping data and renaming - something that we do not always want because from a theoretical point of view order of columns doesn’t matter.
- try to rename object, column
- change type of column (how to convert?)
All of these problems (despite the many advantages) make it not a good approach to database change management.
Versioning transitions
Another approach is to versioning transitions instead of state. In this approach we create sequence of migration scripts which lead us to the desired database state.
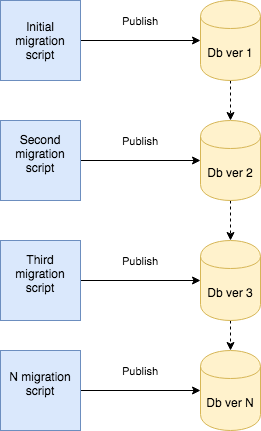
For the example with orders table, instead of change definition we just add migration script as follows:
ALTER TABLE orders.Orders ALTER COLUMN [Name] VARCHAR(70) NOT NULL
GO
ALTER TABLE orders.Orders ADD [Description] VARCHAR(200) NULL
GOIn this approach we should be aware of 2 things:
- order of executing scripts does matter
- is required to store which scripts were executed.
Pros
- Full control of defining transitions
- Executing scripts one by one in correct order guarantees success of deployment to other environments
- Possibility to implement undo/downgrade features
Cons
- Not so easy as change state definition
- Lack of objects history
- Lack of IDE support
- Hardly visible conflicts (2 developers add changes to the same table in 2 separate files)
- Need to keep order of scripts
- Need to keep which scripts were executed
So this is not perfect solution either, has some disadvantages but it is still better than versioning state because we have more control and possibilities. And now we are going to…
Best solution
The best solution is simple but not easy - versioning transitions AND versioning states. :)
If you look at the pros and cons of both solutions you have to admit that they are complementary. By using both approaches you can get rid of all cons leaving advantages.
Well, almost.. :( Combining two approaches costs a little more time and work. You need always create migration script and change definition as well. In addition, you need to be careful about consistency and integrity with two models. Transitions should always lead to defined state. If you have mismatch, you do not know how final schema should look like.
Fortunately a little more work earlier saves you a lot of work later. I worked separately with both approaches in many projects earlier. Now when I combined them I truly feel certain about development and deployment of my databases. I wish I knew it before. :)
Summary
In this post I described:
- how ideal database change mechanism should look like
- state versioning approach
- transitions versioning approach
- the best solution that is a combination of both
In next post I will show how to setup database change management in .NET based on these assumptions.
Comments
Related posts See all blog posts
