Blog
Automated Tests: Strategy

Introduction
In previous posts, I wrote about the reasons to automate software testing and how to achieve a testable architecture.
In this post, I will describe one of the most crucial aspects of software development - testing strategy.
Testing strategy involves determining what we will test, how much we will test, and how we will do it. The strategy will set the direction for us (a roadmap), and the implementation will follow that direction.
“Strategy without tactics is the slowest route to victory. Tactics without strategy is the noise before defeat.” Sun Tzu.
Evaluation criteria
As we well know, every decision related to software architecture results in some quality attributes being better fulfilled at the expense of others. The same applies to the world of automated testing. One approach may have advantages in one area, while in another, it may not work at all.
For this reason, there is no one universal, always effective approach to test automation. However, there are general principles and rules that are worth following when creating an optimal testing strategy in a given context.
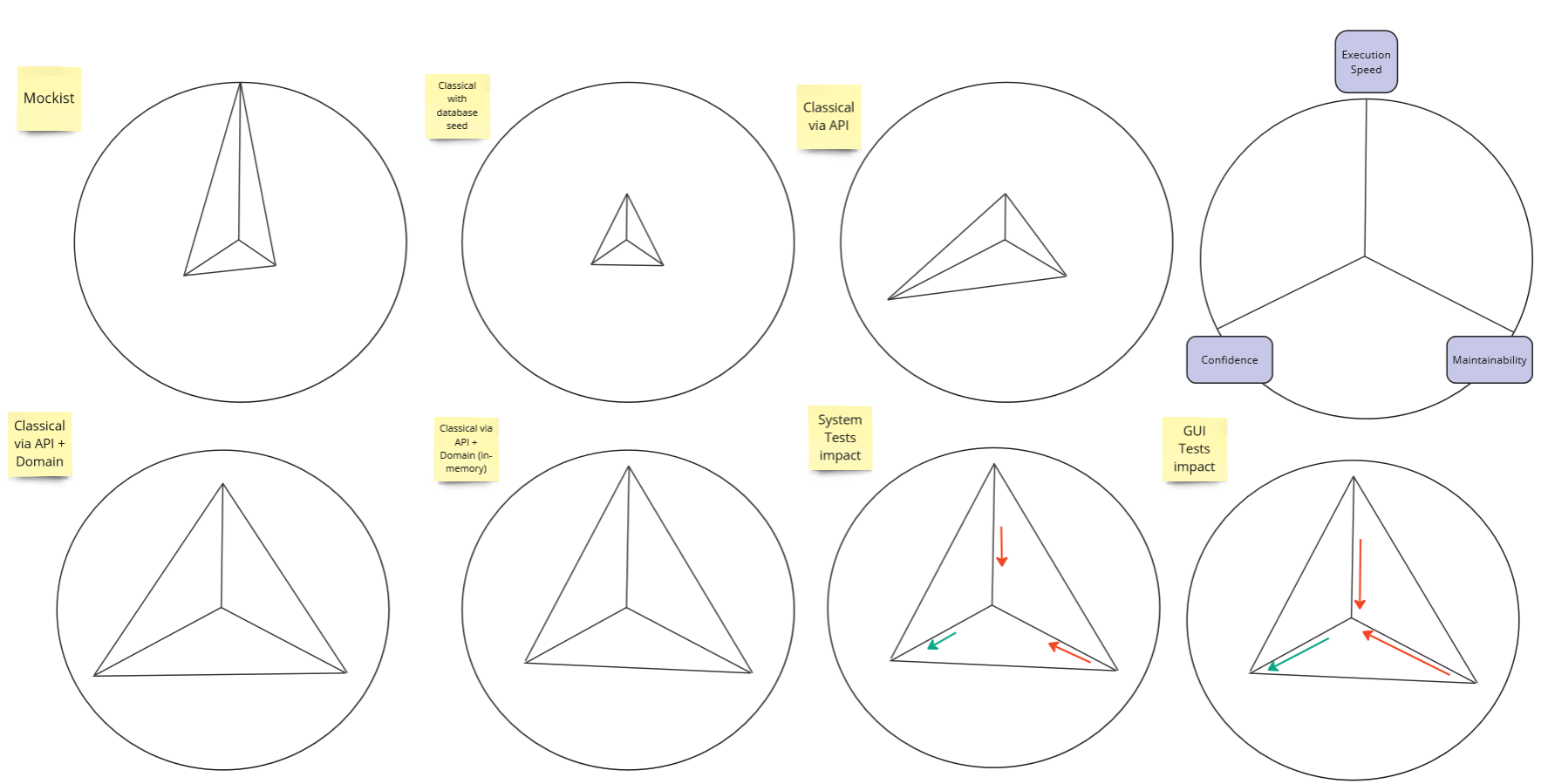
I will discuss these principles using an example, where I will go through various approaches and techniques related to automation, evaluating each of these techniques based on three criteria:
-
Certainty - to what extent do my tests give me confidence that the system works according to the requirements specification? Am I sure that the system does not have critical errors? Does the fact that tests are positive mean that I can deploy the system and release functionality? Do I trust my test suite?
-
Execution speed - how quickly do tests run? How long do I have to wait for positive verification? Can I parallelize the tests? What is the feedback loop duration?
-
Maintainability - how easy is it to maintain a set of tests? Does a small change in requirements require a large number of test changes? Does a change in implementation require a test change? Are the tests fragile? Are tests easy to write and, more importantly, understand later on?
Example
Let’s consider the testing strategy for the following use case. Let’s assume we want to automatically test the “Generate an Offer” use case. In this case, we are not focusing on what offer we will generate — it could be any item (a car, furniture, etc.).
Generating an offer involves the following steps:
-
Check if the item is available in the warehouse. We assume this information exists in an external system, and we need to retrieve it through an appropriate service.
-
Retrieve data for calculating the offer. We assume all the data needed for the offer calculation is in our system’s database.
-
Calculate the offer by performing calculations in the application.
-
Save the offer — permanently store the entire offer in the database.
-
Send an email with the offer, informing the customer about their offer.
Let’s look at the diagram of how such a process looks:
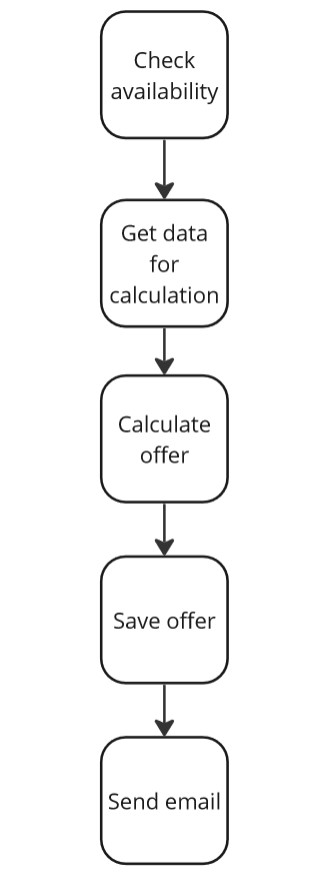
Generate Offer use case.
We will also examine how pseudocode for implementing such a use case might look:
public void GenerateOffer(OfferData offerData)
{
var isAvailable = // Direct API CALL.
if (isAvailable)
{
var dataToCalculation = // SQL statements to get data
var offer = // Offer calculation logic
// SQL statement to save offer
// SMTP client execution to send email
}
}Let’s think about what would be an optimal testing strategy for such a use case.
Before that, however, it is crucial to consider the type of dependencies we have, as this will impact our strategy. According to the description, external services are responsible for checking availability and sending emails. Our own database is responsible for storing and retrieving offer data:
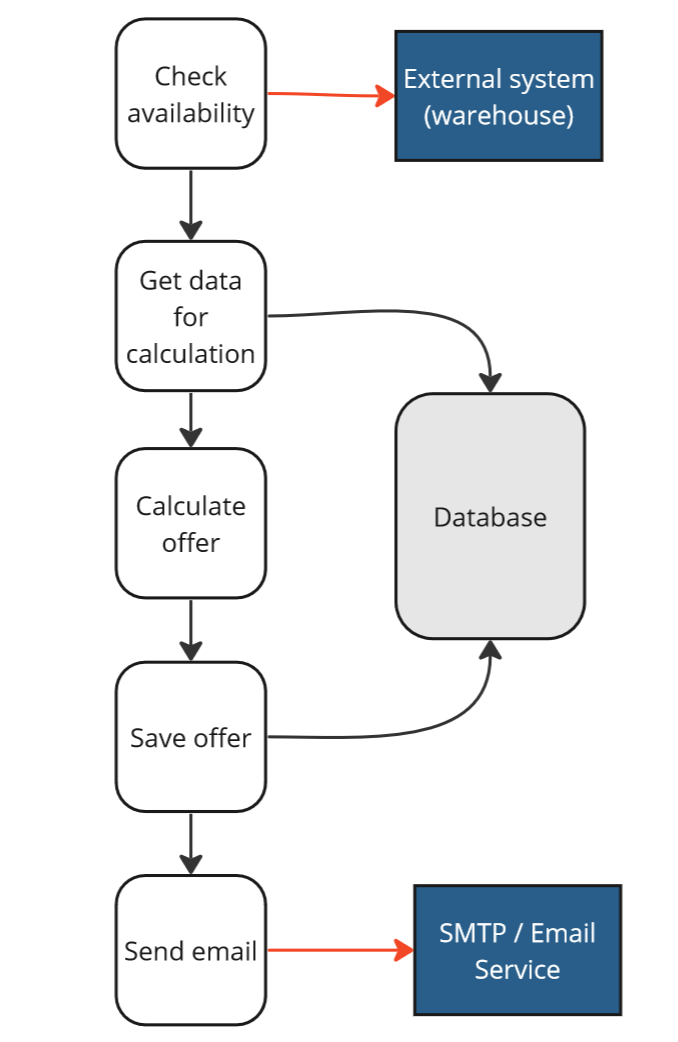
Generate an Offer use case - collaborators.
Strategy 0 - No Automation
First and foremost, we always need to ask ourselves whether it’s worth automating a particular use case. There are cases where the cost of automation, due to various factors, is so high that it’s better not to introduce automated tests. From my experience, however, this situation is very rare, and the lack of automated tests is more often a result of neglect and excuses.
Let’s assume that we don’t want to introduce automated tests. If this happens, every change in our system will require manual tests to validate the process. If we skip or make a mistake during manual testing, it may turn out that a certain functionality doesn’t work. This could be due to an error in various places, for example:
-
Availability check - we expected a
trueorfalsevalue from an external system, but received0or1. -
Retrieving data for offer calculation - we made a mistake in writing the SQL script.
-
Offer calculation - we made a logical error in the calculation.
-
Saving the offer - we incorrectly mapped our offer object to a table in the database in our ORM.
-
Email sending - during sending, we switched the subject of the message with the content.
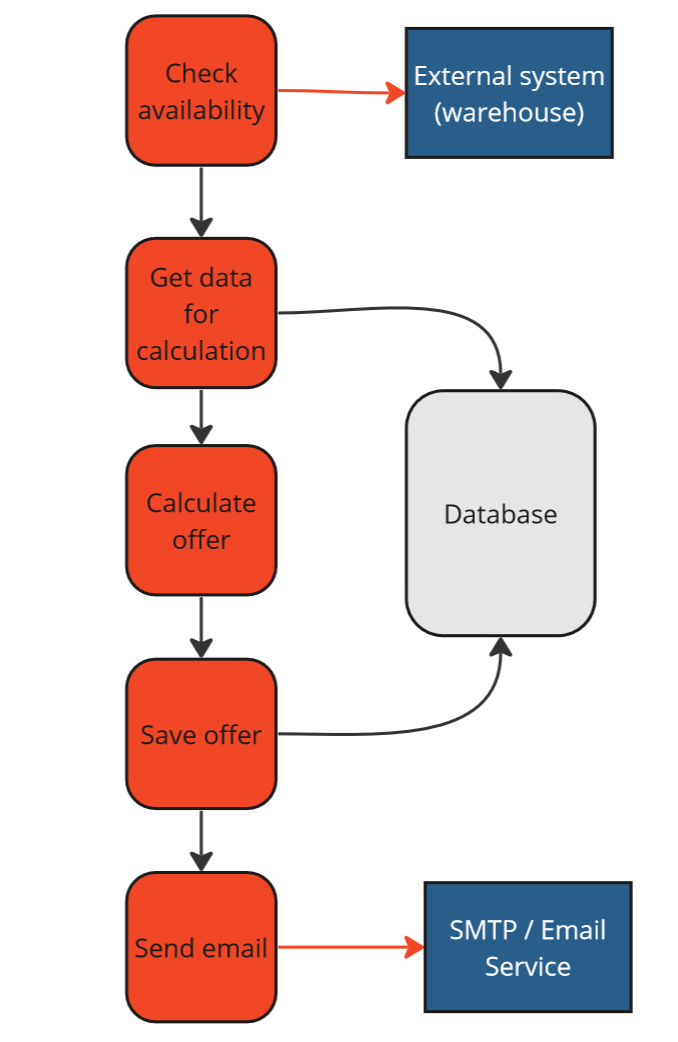
Generate an Offer use case - no automation.
As you can see, many things could go wrong. If we want to work evolutionarily, take advantage of the benefits of continuous delivery, and quickly deploy and release subsequent changes, we cannot do it without automated tests in this case. Let’s see how we can do that.
Strategy 1 - Mockist (London)
The first strategy we’ll adopt involves the use of mocking (the so-called London school / Mockist). This school suggests that we should become independent of all collaborators and, in doing so, test our use case in complete isolation.
Based on the previously shown pseudocode, we are unable to isolate ourselves from dependencies immediately. Therefore, we need to introduce intermediary objects at the beginning:
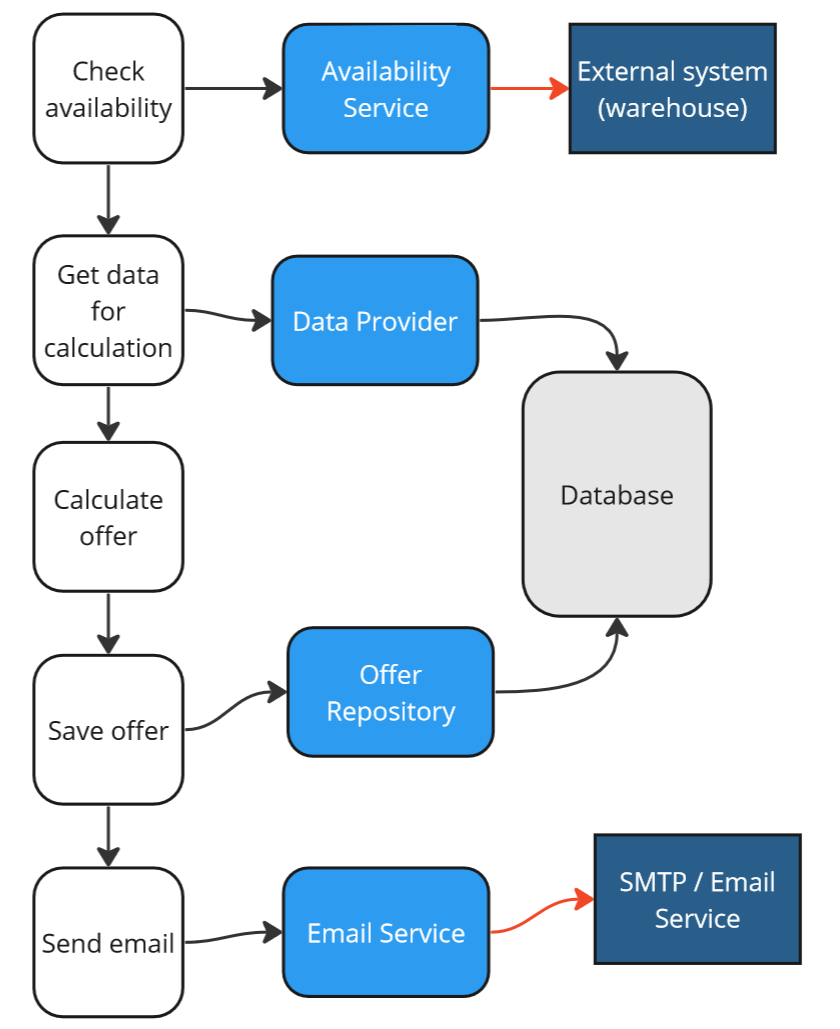
Generate an Offer use case - Middlemen.
We will be able to substitute these objects during tests, isolating ourselves from real dependencies. Even though this is a mockist school, it’s worth distinguishing between two types of intermediary objects in this case, as Gerard Meszaros writes in his book:
-
Stub - objects that allow us to isolate from dependencies and enable testing but are not objects of verification. We set them up in preparing the System Under Ttest (GIVEN section), but do not use them in assertions (THEN section).
-
Mock - objects that allow us to isolate from dependencies, enable testing, and are objects of verification. We will set them up in preparing the SUT (GIVEN section) and use them in assertions (THEN section).
In the example, _availabilityService and _dataProvider are stubs, while _offerRepository and _emailService are mocks:
Let’s see how the pseudo-production code would look now:
public void GenerateOffer(OfferData offerData)
{
var isAvailable = _availabilityService.Check(offerData.ProductId);
if (isAvailable)
{
var dataToCalculation = _dataProvider.GetDataForCalculation(...);
var offer = CalculateOffer(dataToCalculation);
_offerRepository.Add(offer);
_emailService.SendEmail(...)
}
}
public void Test()
{
// Given
_availabilityService.Check().Returns(true); // Stub
_dataProvider.GetDataForCalculation(...).Returns(data); // Stub
_offerRepository.Setup(); // Mock setup
_emailService.Setup(); // Mock setup
// When
GenerateOffer(offerData);
// Then
_offerRepository.Add(offer).ExecutedOnce() // Mock verification
_emailService.Add(offer).ExecutedOnce() // Mock verification
}Full isolation gives us the opportunity to test the use case entirely in memory. I define such tests as unit tests (there is no common clear definition for unit testing in the community).
These will be the fastest type of tests. Additionally, in the case of an error, we will immediately know which component is not working correctly.
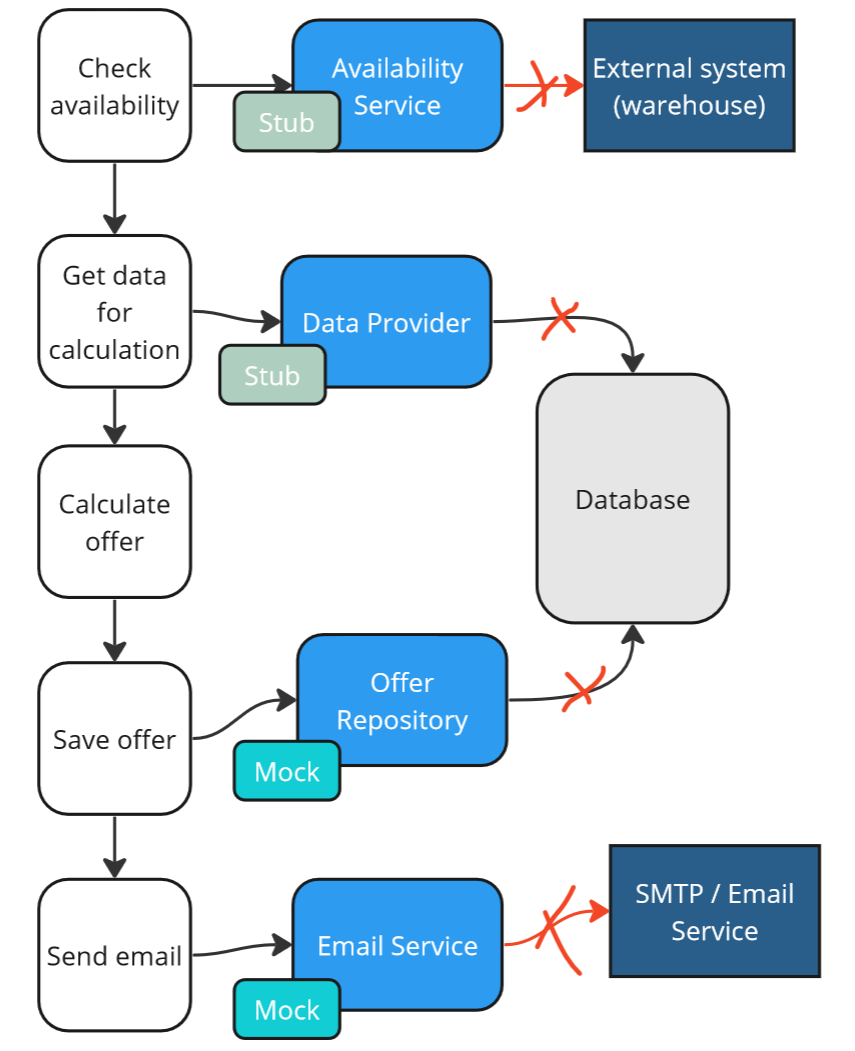
Generate an Offer use case - Middlemen: stubs and mocks.
However, with such a testing strategy, can we be sure that our system works according to the assumptions? Can we deploy it to production?
Unfortunately, in reality, we have tested only the orchestration of the process itself, and there is still a probability of errors in the components we’ve stubbed. Our tests may be green, but critical errors may still occur in production. We will have false negatives tests.
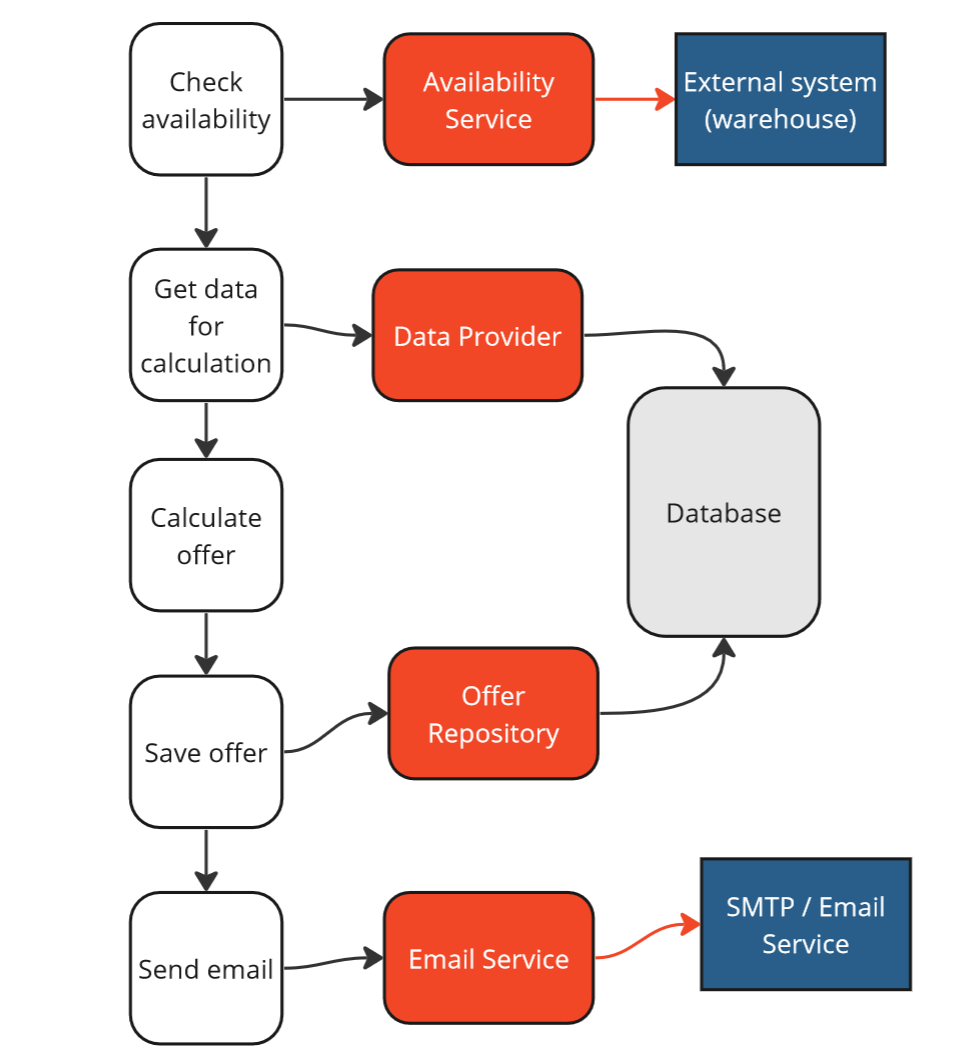
Strategy 1 - Mockist - validation.
Furthermore, tests from the London school cause the implementation details to leak into the tests. As you can see, our test is aware that we have objects like _dataProvider and _offerRepository, which are implementation details. If we want to change or remove these objects, we will also have to change our tests simultaneously. As a result, the maintainability of our tests decreases.
Ultimately, the evaluation of such a strategy is as follows:
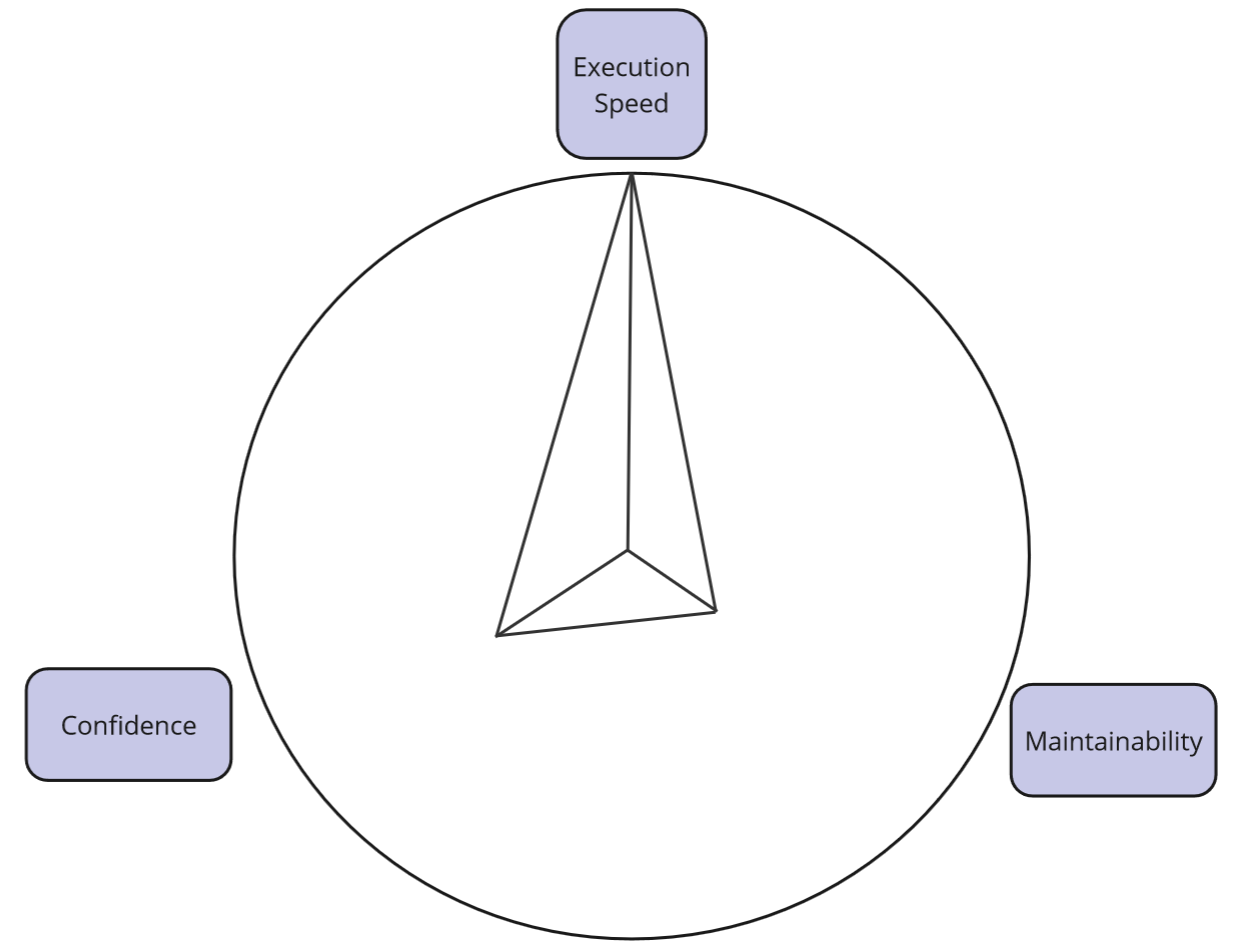
Strategy 1 - Mockist - evaluation.
As you can see, the tests are super fast, but unfortunately, they do not provide sufficient confidence, and maintaining them can be challenging. Let’s see what we can do about it.
Strategia 2 - Classical with a database seed
Since the mocking approach did not yield optimal results, let’s try the so-called classical approach (aka Chicago school).
We won’t use stubs and mocks for dependencies we control. Instead, we will conduct tests on real dependencies, stubbing and mocking only those dependencies that we don’t control.
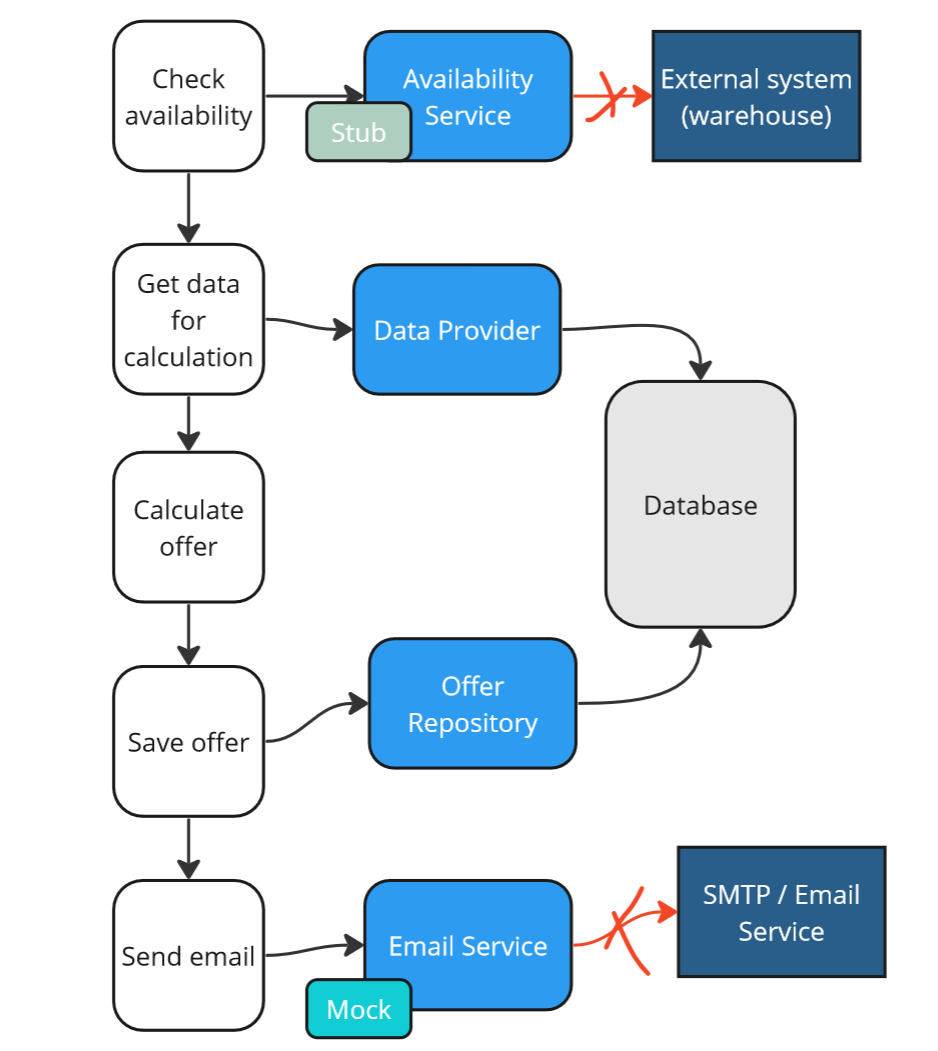
Strategy 2, classical approach - use real, controllable dependecies.
This approach will allow us to perform tests at the level of our module. I refer to such tests as integration tests.
PS: Integration tests are another very broad, non-uniform definition. Some people call it component testing. Call them whatever you want, just be consistent - they are tests that test one coherent logical whole.
Isolation from external systems is necessary for the tests to be deterministic and much easier to run and maintain.
Let’s see the code:
public void Test()
{
// Given
_availabilityService.Check().Returns(true); // Stub
_emailService.Setup(); // Mock setup
Database.Seed(…); // Write to real database.
// When
Handle(command);
// Then
var data = Database.GetData(); // Assert against real database.
Assert(data);
_emailService.Add(offer).ExecutedOnce() // Mock verification
}
As seen in this case, in the GIVEN section, we seed the database that we set up on our testing infrastructure (e.g., in a docker container), and in the THEN section, we retrieve information using queries that serve us in further assertions.
These tests will be significantly slower than those in memory because we are connecting to a database. However, at first glance, it seems that this time we are quite confident that the system will work correctly in production.
Unfortunately, that’s not true! It’s even worse than before. Why? Because we are testing the state of the system that may never occur in production! All thanks to reproducing the system state directly through the database. Our tests only obscure the picture and make our confidence increase, but in reality, we expose ourselves to errors in production. Again, false negatives.
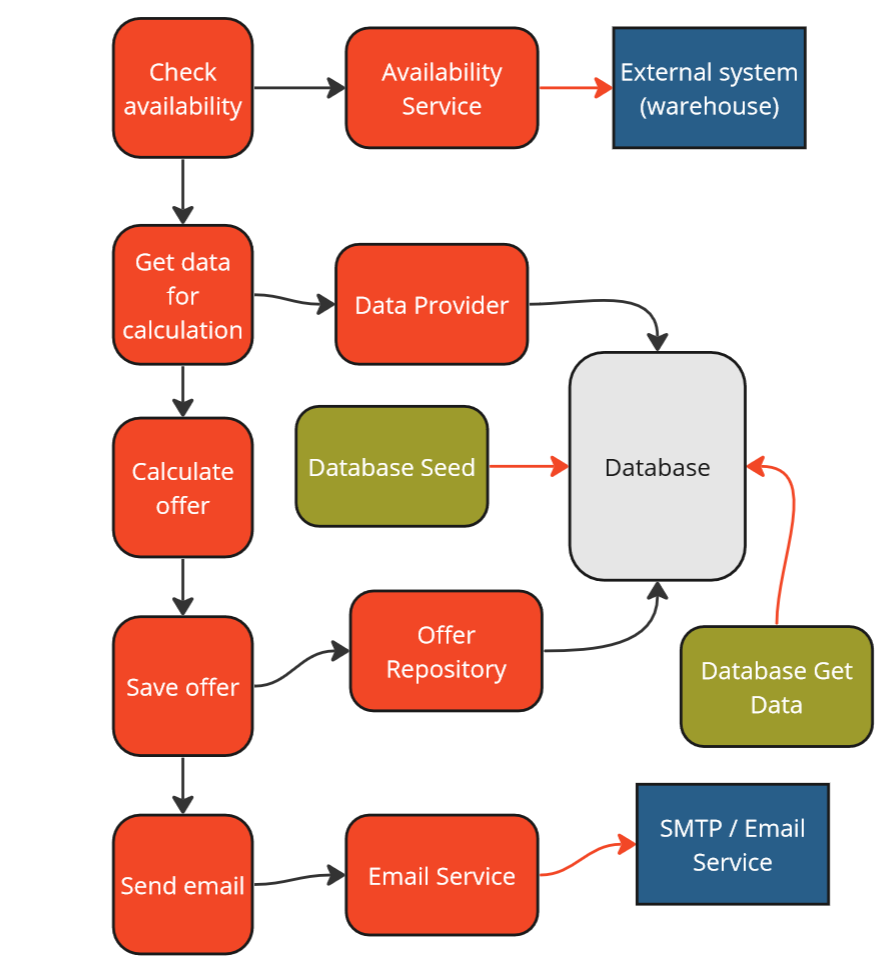
Strategy 2, classical approach with a database seed - everything could not work on production.
Furthermore, the maintainability of the tests has also decreased because our tests depend on changes in the database structure – that is, on the implementation.
Strategy 2, classical approach with a database seed - evaluation.
In summary, we have increased execution time, reduced confidence, and decreased maintainability – this is not a good strategy at all!
Strategy 3 - Classical using API
Strategy 2 turned out to be highly ineffective, but we can easily make it work to our advantage. All we need to do is leverage good practices such as higher-level encapsulation, and instead of creating the System Under Test (SUT) from the database level, use the API of our system/module – because that’s how it will work in production.
Basing our tests on the API:
- we are confident that if the tests work for us, the system in production will likely work as well.
- we rely on abstraction rather than implementation details, making such tests easier to maintain.
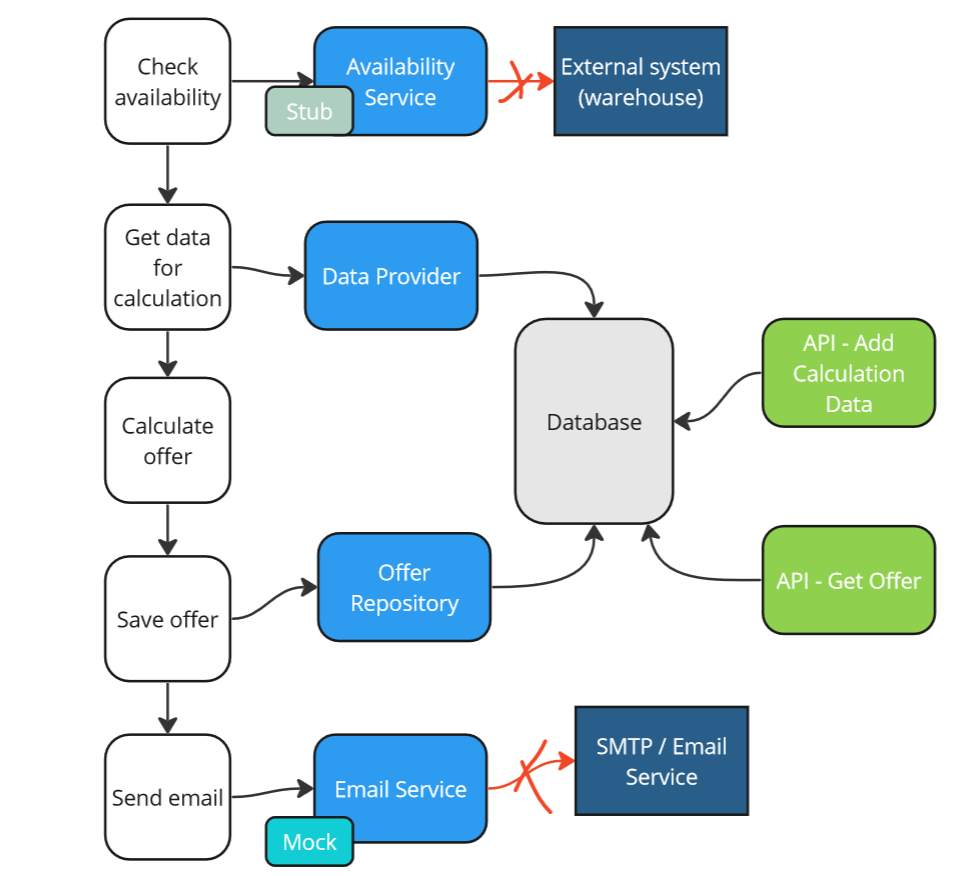
Strategy 3 - classical approach using API.
public void Test()
{
// Given
_availabilityService.Check().Returns(true); // Stub
_emailService.Setup(); // Mock setup
Api.AddData(…) // Module's API usage
// When
Handle(command);
// Then
var data = Api.GetOffer(…); // Module's API usage
Assert(data);
_emailService.Add(offer).ExecutedOnce() // Mock verification
}
In this way, we have increased confidence in the system’s operation in production and made the tests easier to maintain. We are confident that we are replicating the system state to a large extent from production.
Seeding directly into the database is one of the most common mistakes made in test automation. The less our setup resembles production, the lower the confidence in our solution.
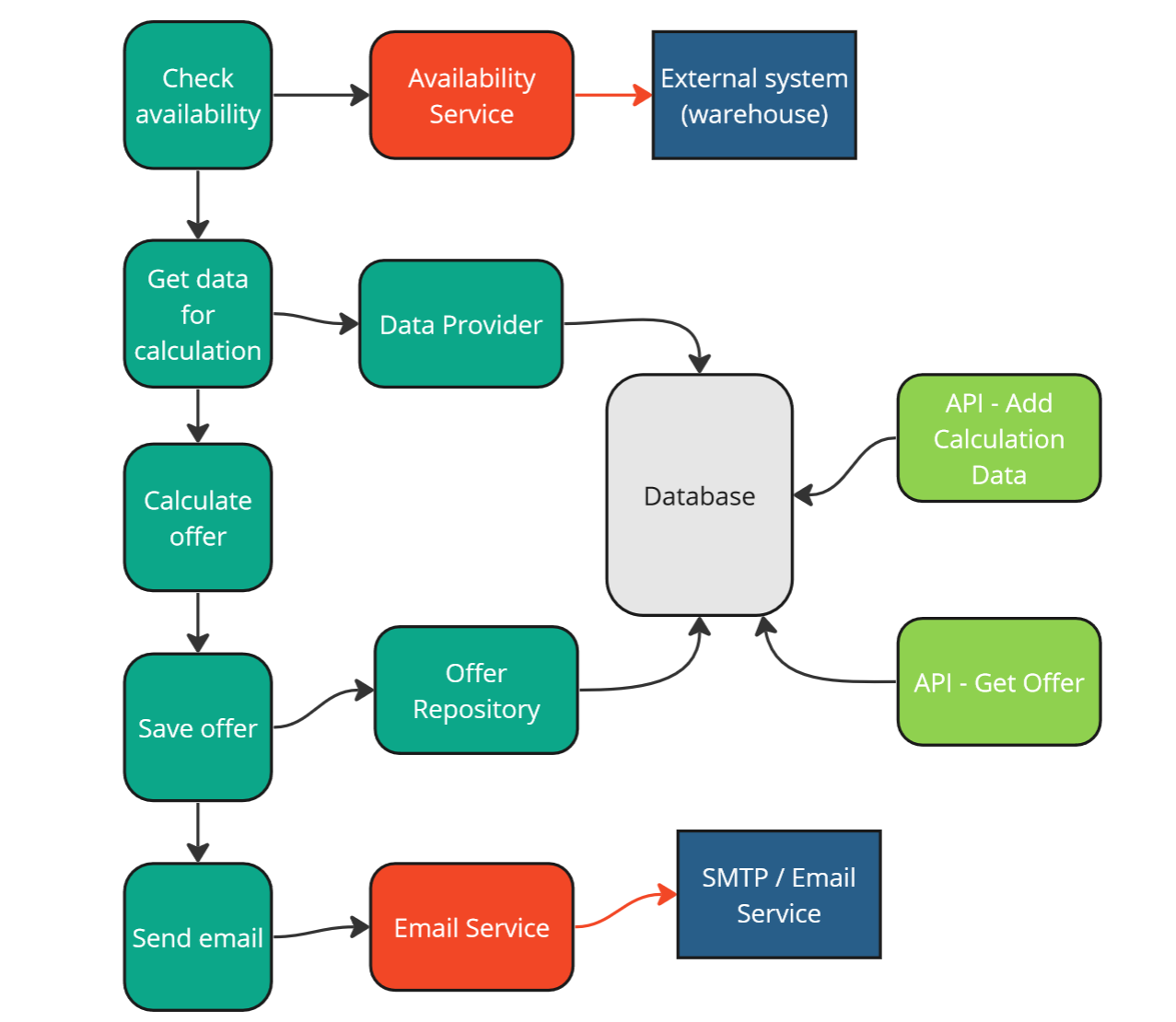
Strategy 3 - classical approach using API - validation.
The speed of our test suite remained unchanged compared to strategy number 2, but we will address that in the next point.
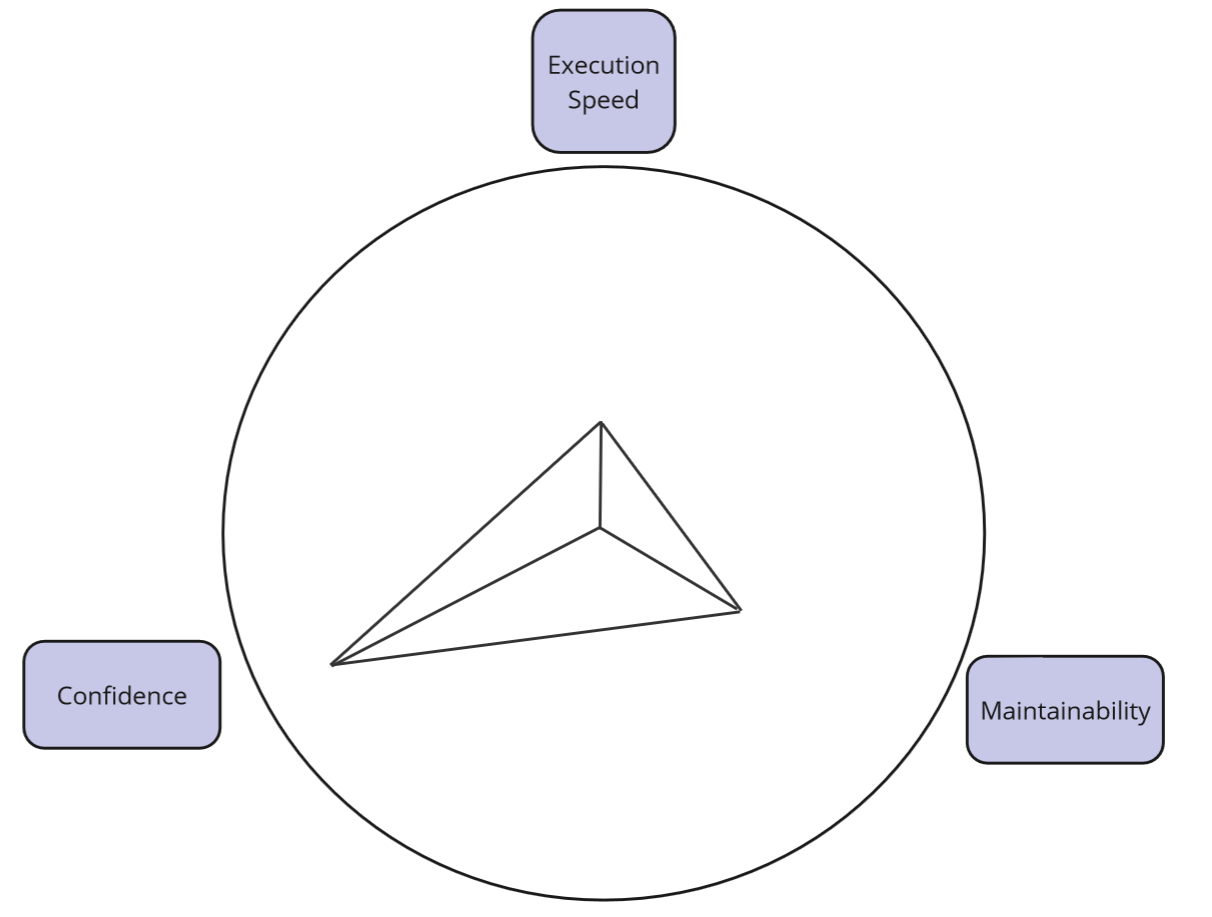
Strategy 3 - classical approach using API - evaluation.
Strategy 4 - Classical using API + Domain
Strategy number 3 looks promising, but it’s not ideal for more complex projects. We definitely want to further increase the maintainability of tests and reduce their execution time. How can we achieve this?
Here, the Domain and unit testing (in-memory) come to our aid. If we manage to extract domain concepts and business logic into the domain (using Domain-Driven Design tactical patterns for instance), we can test our domain at the unit level.
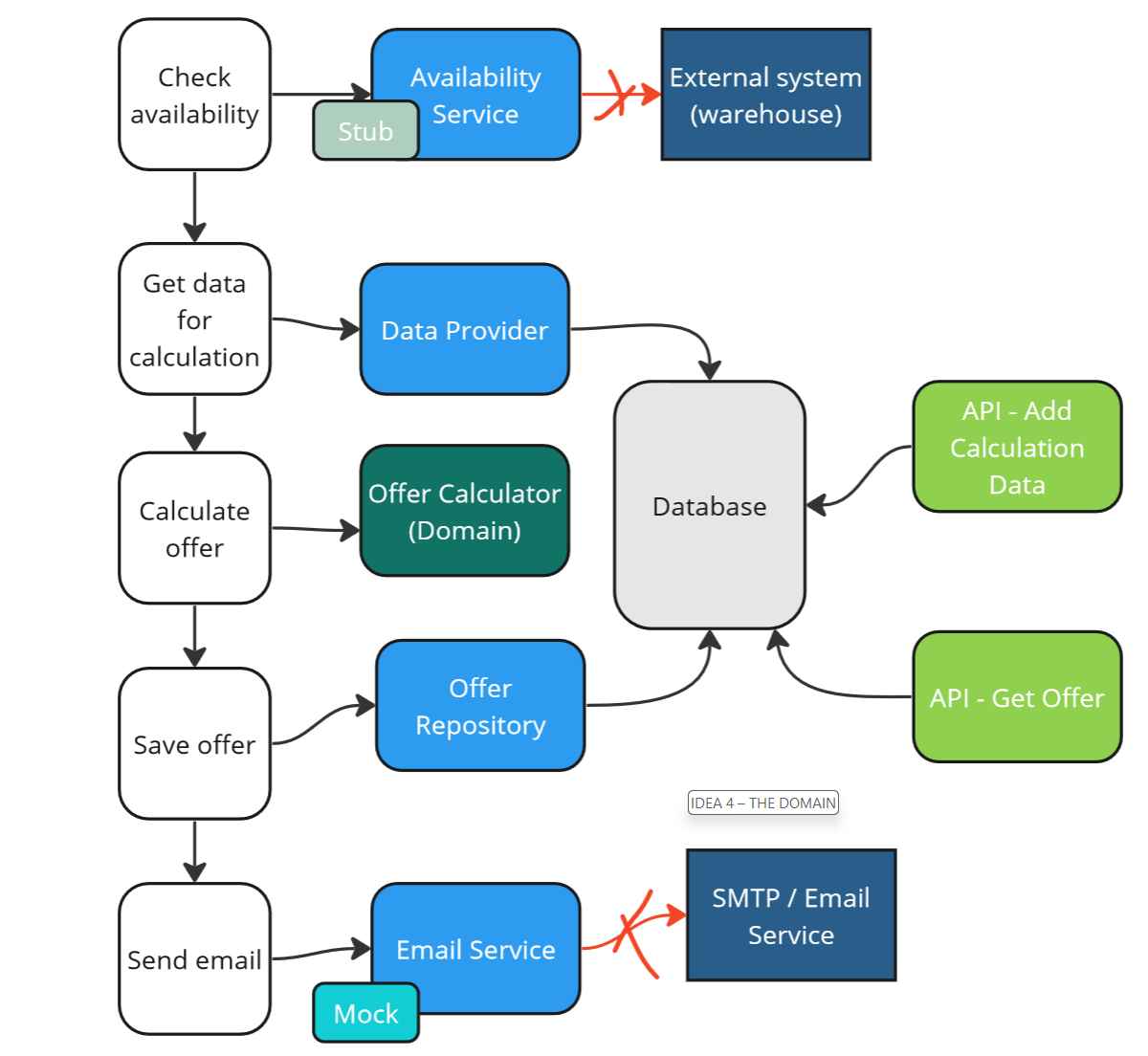
Strategy 4 - classical approach using API + Domain.
These unit tests will be much faster and easier to maintain than heavier integration tests. Does that mean we should give up on the latter? Of course not. Unit tests verify our Domain, while integration tests cover individual use cases and communication with dependencies under our control.
In our example, we can extract the concept of an `Offer Calculator“, write it in the form of a pure function, and unit test all permutations. Integration tests will ensure that data is passed correctly to the calculator but won’t test all the variants – that’s covered by the unit tests.
public class OfferCalculator
{
public Result Calculate(input)
{
var discount = 0;
if (input.IsVip)
{
discount = 0.2;
}
...
}
}
public void Test()
{
// Given
var inputData = new InputData(...);
// When
var result = OfferCalculator.Calculate(inputData);
// Then
Assert(result);
}
With this approach, some integration tests will become unit tests, providing us with:
- greater confidence - we can test more
- greater maintainability - memory tests are easier to setup
- greater execution speed.
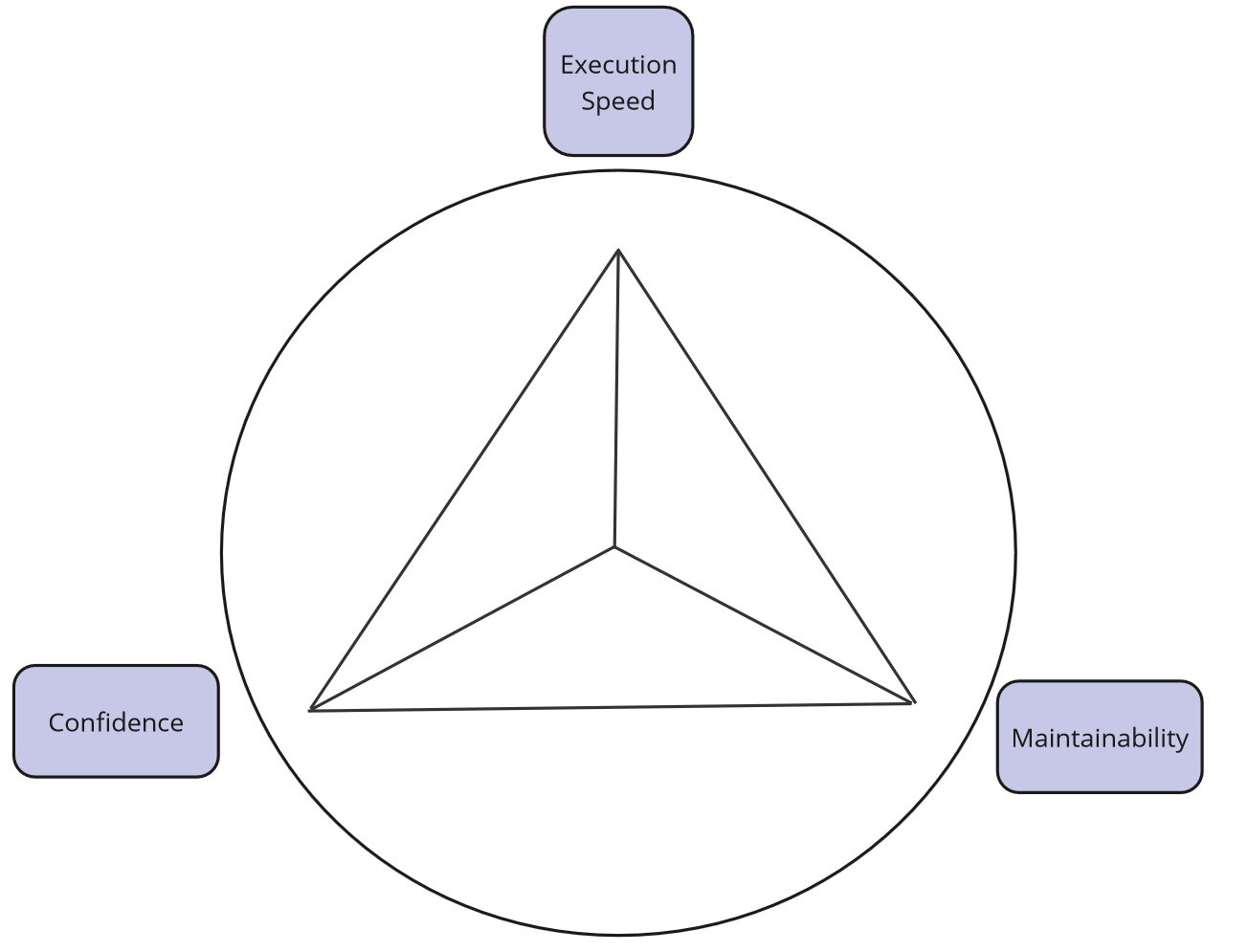
Strategy 4 - classical approach using API + Domain - evaluation.
Strategy 4 alternative with in-memory database
We can modify Strategy number 4 in certain situations if we prioritize the speed of tests over the certainty of the system working correctly by introducing an in-memory database instead of a real one.
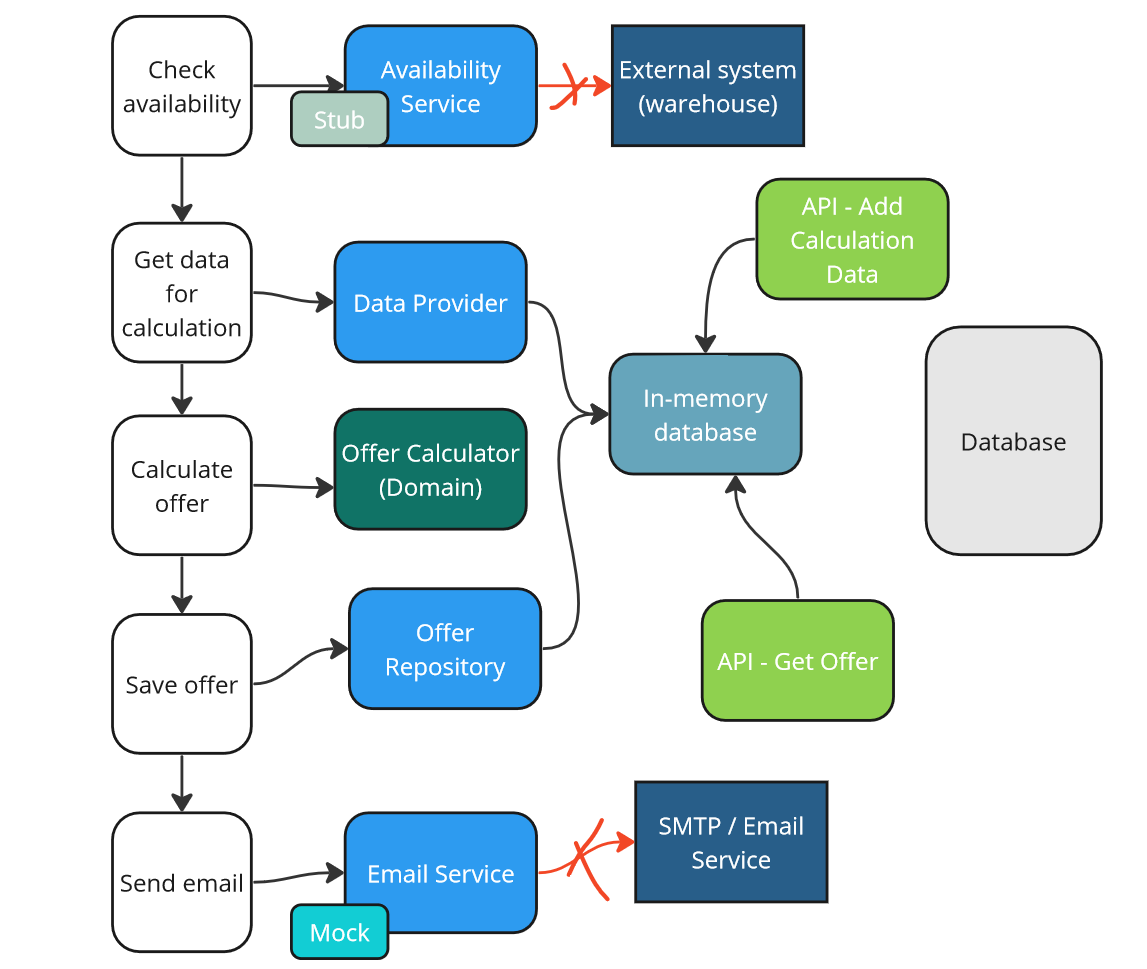
Strategy 4 alternative - classical approach using API + Domain + in-memory database.
This solution will significantly speed up the tests, but we won’t have 100% certainty that the system will function correctly in production. There will always be some differences between an in-memory database and a real one – we need to be aware of this.
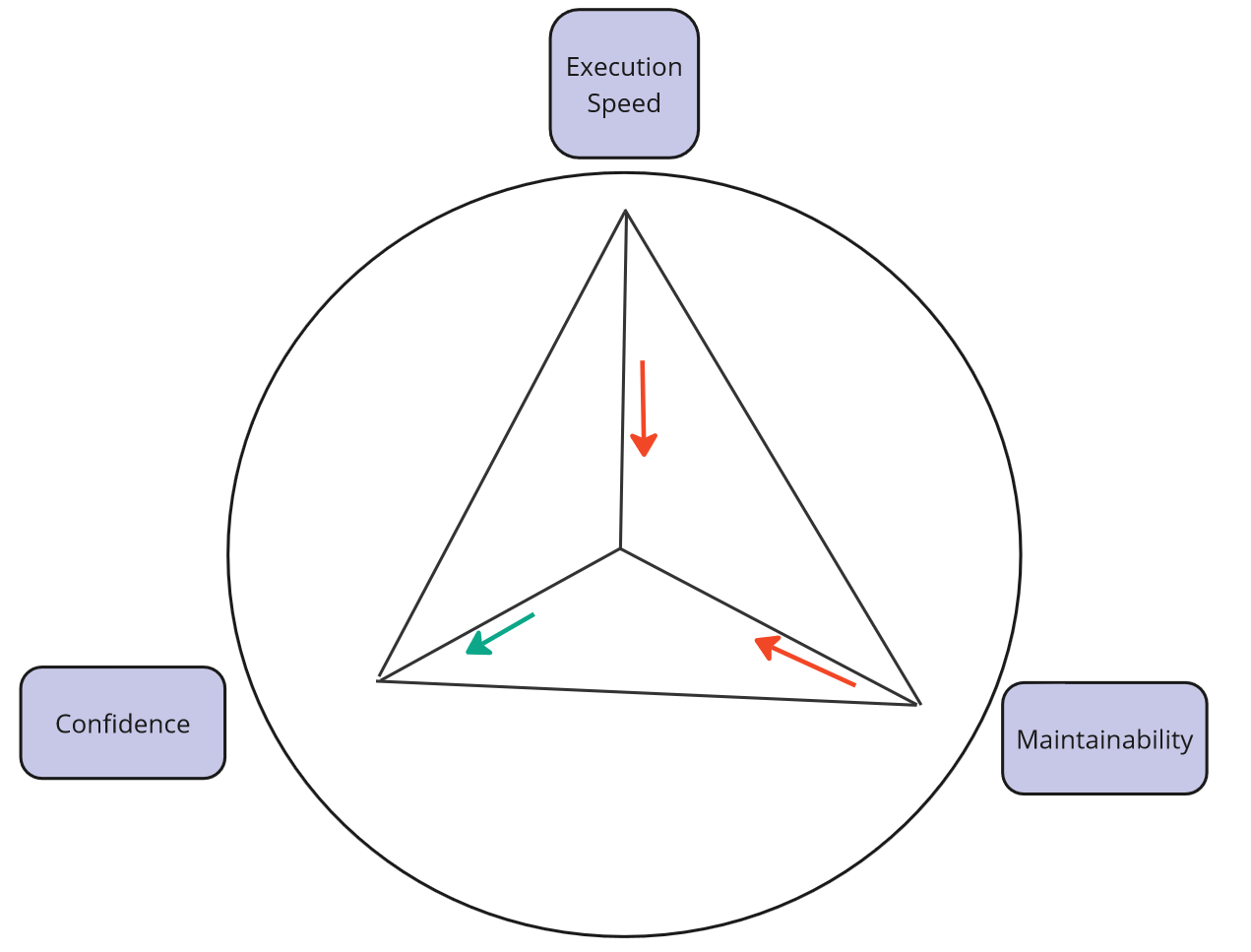
Strategy 4 alternative - classical approach using API + Domain + in-memory database - evaluation.
Another alternative is a hybrid model. For pipelines running on every commit, we can use an in-memory database, while using the real database occasionally or before deployment. The downside to this solution is that the feedback loop indicating incorrect operation is longer, affecting the team’s workflow and potentially hindering optimal Continuous Integration and Delivery.
System Tests
So far, I’ve been discussing tests for specific individual parts of the system (modules). However, such tests are not sufficient; therefore, we should also automate the actions of the entire system with dependencies that are not under our control. System tests serve this purpose, and the question is, how many of them should there be?
If we choose a good testing strategy (testing our modules in isolation), the number of system tests should equal the number of integrations between these modules. The more communication between modules (whether synchronous, e.g., through REST, or asynchronous, e.g., through events), the more such tests we need to write.
That’s why it’s crucial to test modules in isolation as much as possible, similar to the relationship between unit and integration tests – the more unit tests we write, the fewer integration tests we need to cover our cases. Similarly, the more we have tested at the module level, the fewer tests we need to perform at the level of the entire system.
Why do we want as few system tests as possible? It’s because their maintainability is very low – setting them up is difficult, and they perform a lot of tasks.
Additionally, they are very slow – communication with all modules/services takes much longer, and we have little control over it.
Moreover, system tests are often challenging to automate, as attempting to introduce determinism using dependencies that are difficult to control can be very costly.
Contract tests are also increasingly used (popular in distributed environments), which means that the number of system tests can be reduced even further.
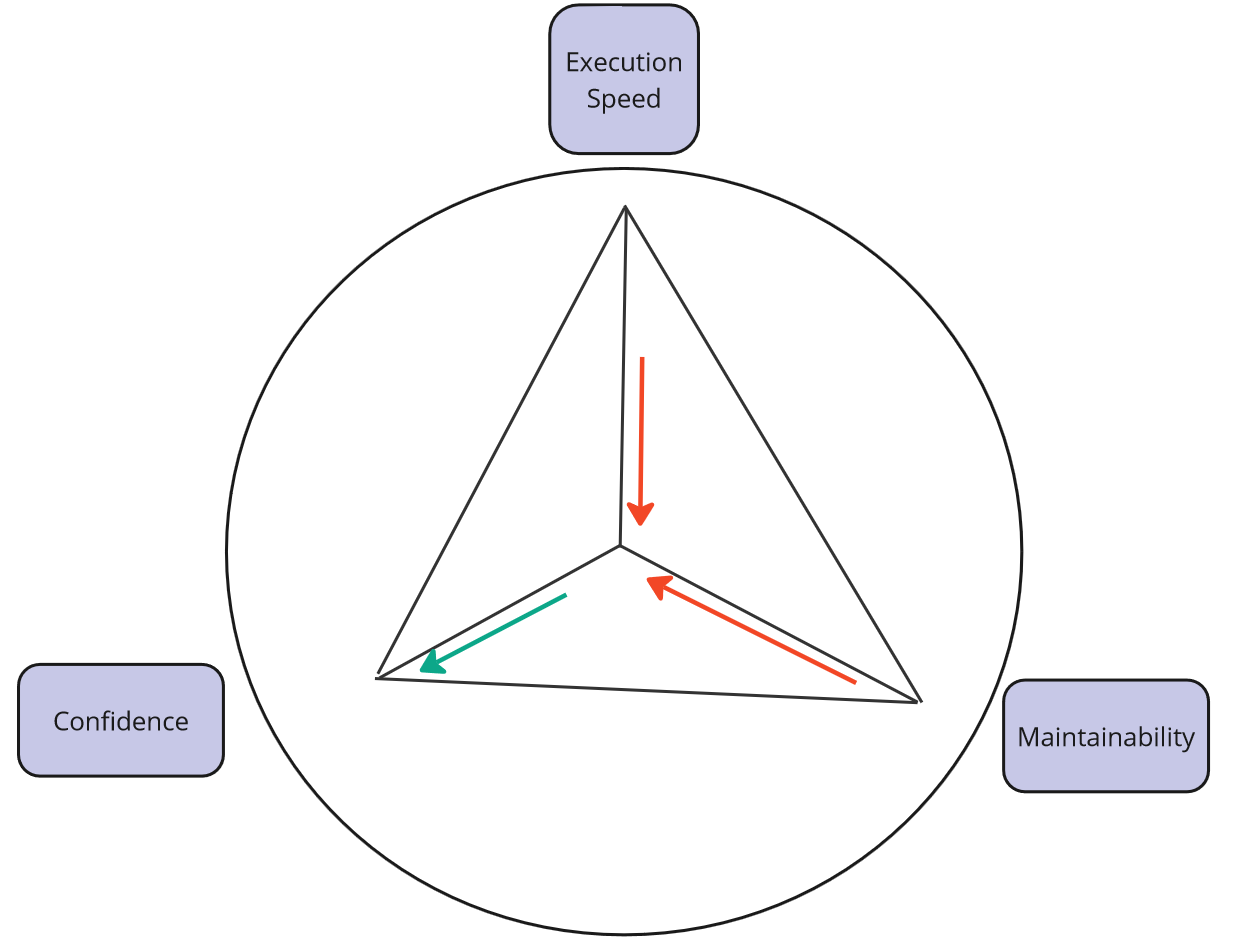
System Tests - evaluation.
GUI Tests
Lastly, I would like to analyze tests through the graphical user interface (GUI).
I intentionally avoid using the term “End-to-End” tests here because such a designation is ambiguous. For one person, it may mean tests through the graphical user interface, while for another, it may refer to tests of the underlying API.
The main advantage of GUI tests is that they provide even greater confidence that our system is functioning correctly. On the other hand, they come with several disadvantages:
- They are very slow.
- They are challenging to prepare.
- They are difficult to maintain – often, a change in the graphical user interface without a change in business logic requires a test modification.
- Often, they do not allow testing certain system behaviors because those behaviors are not triggered through the graphical user interface (e.g., handling messages from an external system).
GUI Tests - evaluation.
For these reasons, GUI tests should be used with caution. Unfortunately, the trend I observe in the Testing/QA community and generally in project teams is that the automation of manual tests mainly involves automating tests through the graphical user interface.
In my opinion, this is a significant mistake for the reasons I described above and considering the overall testing strategy. Such tests make our system hard to change, increase project costs, and prevent us from utilizing other levels of testing in this scenario. Our strategy in this case is not optimal.
I definitely don’t consider such tests unnecessary. They are needed like any other level of testing, but their quantity should be carefully chosen, well thought out, and limited.
Summary
-
Testing strategy should consider optimizing the three main factors – the confidence provided by tests, their speed, and maintainability.
-
Tests that mock/stub all dependencies (mockist aka london school) do not give us sufficient confidence that the system will work correctly.
-
Introducing integration tests and testing on real dependencies (classical, chicago school) increases confidence in the system’s operation. However, it only makes sense when our test setup is the same as in production. We should always refer to the API of our module.
-
Integration tests alone provide high confidence, but their speed and maintainability are not efficient.
-
To increase the maintainability and speed of the entire test suite, introduce unit tests that operate in-memory and effectively test our domain. To achieve this, use an appropriate architecture that is domain-driven and allows the introduction of such tests.
-
Striking the right balance between unit tests (domain tests) and integration tests (use case tests and dependencies) is a crucial aspect of the testing strategy.
-
We can use in-memory databases to increase tests speed. However, it will reduce our confidence in the system’s operation in production. We can adopt a hybrid approach too, which prolongs the feedback loop.
-
System tests are slow and challenging to maintain, so apply them to test the system as a whole only at points of integration. Consider other approaches as contract testing.
-
GUI tests provide high confidence but are very slow and more challenging to maintain. A minimal number of GUI tests should be written with caution.
Tests Strategy - summary.
Recommended reading
More in series
This post is part of the Automated Tests series:
Comments
Related posts See all blog posts