Blog
Automated Tests: Testability

Introduction
In the first post of a series of articles about automated tests, I wrote about the reasons to implement them in our software engineering process.
Before I delve into the testing strategy, it’s important to discuss testability as one of the more important aspects of an evolutionary architecture and a testable architecture in general.
Testability
To quote wikipedia, testability is:
“The degree to which a software artifact (i.e. a software system, software module, requirements- or design document) supports testing in a given test context.”
In other words, considering it in the context of our system, if our system has high testability, it means that it is easier to test. On the other hand, if the testability is low, it will be harder for us to test it.
According to one definition of software testing:
“Software testing is the act of examining the artifacts and the behavior of the software under test by validation and verification.”
It follows that with low testability, it will be more difficult for us to verify and validate our system. This means that its quality will be lower and/or its cost will increase significantly.
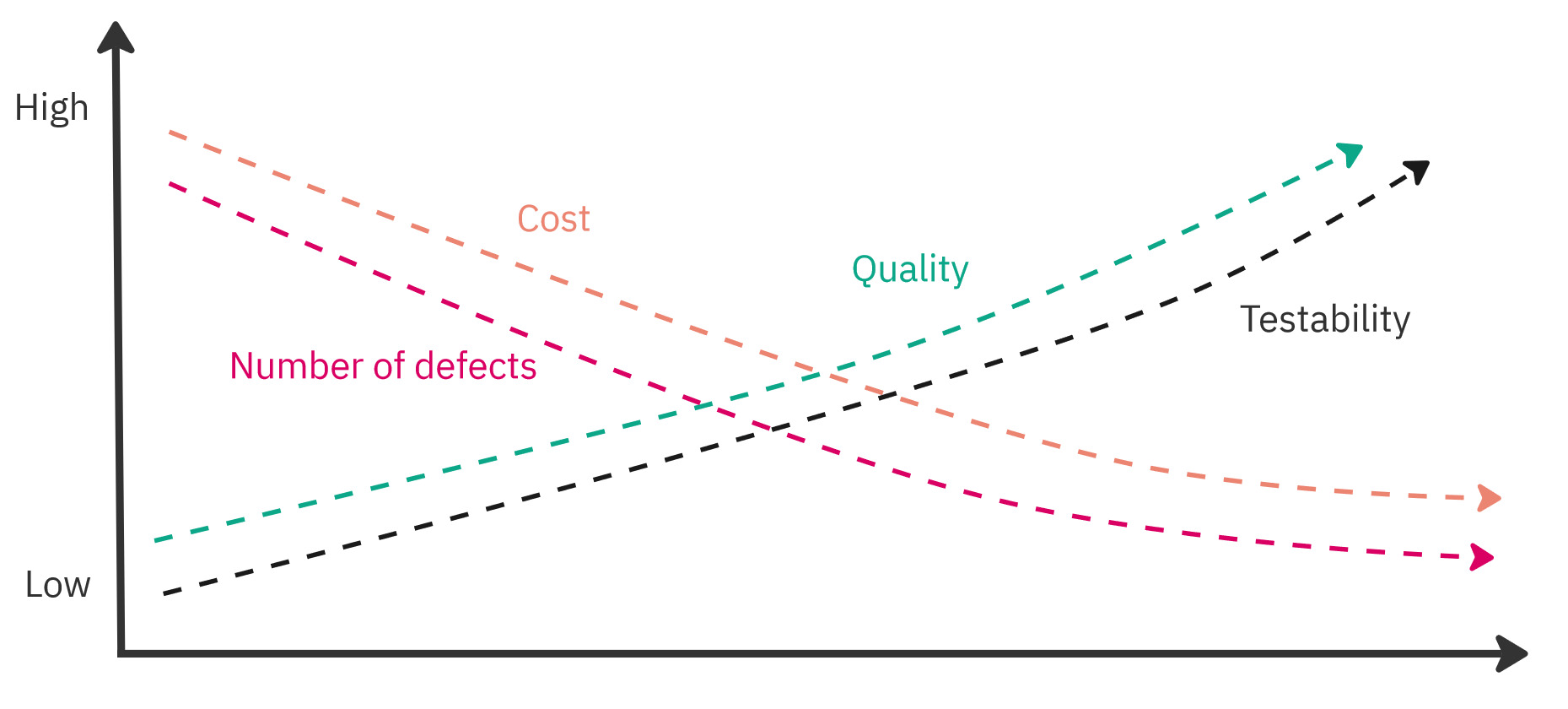
Testability vs other factors.
As you can see, testability is an important attribute of our architecture, and in some situations, it can determine the success or failure of a given project. It will be even more important if we want to deliver our software quickly in an evolutionary way, using a Continuous Delivery approach. Quoting a great book Accelerate on modern software engineering practices:
“It appears that these characteristics of architectural decisions, which we refer to as testability and deployability, are important in creating high performance.”
Testability, however, is a larger concept, so let’s try to break it down into smaller components to understand it better.
Controllability
The first factor affecting testability is controllability. Controllability is a measure of how much we are in control of our system.
What does it mean to control the system? We can imagine a system as a finite set of states and transitions between them.
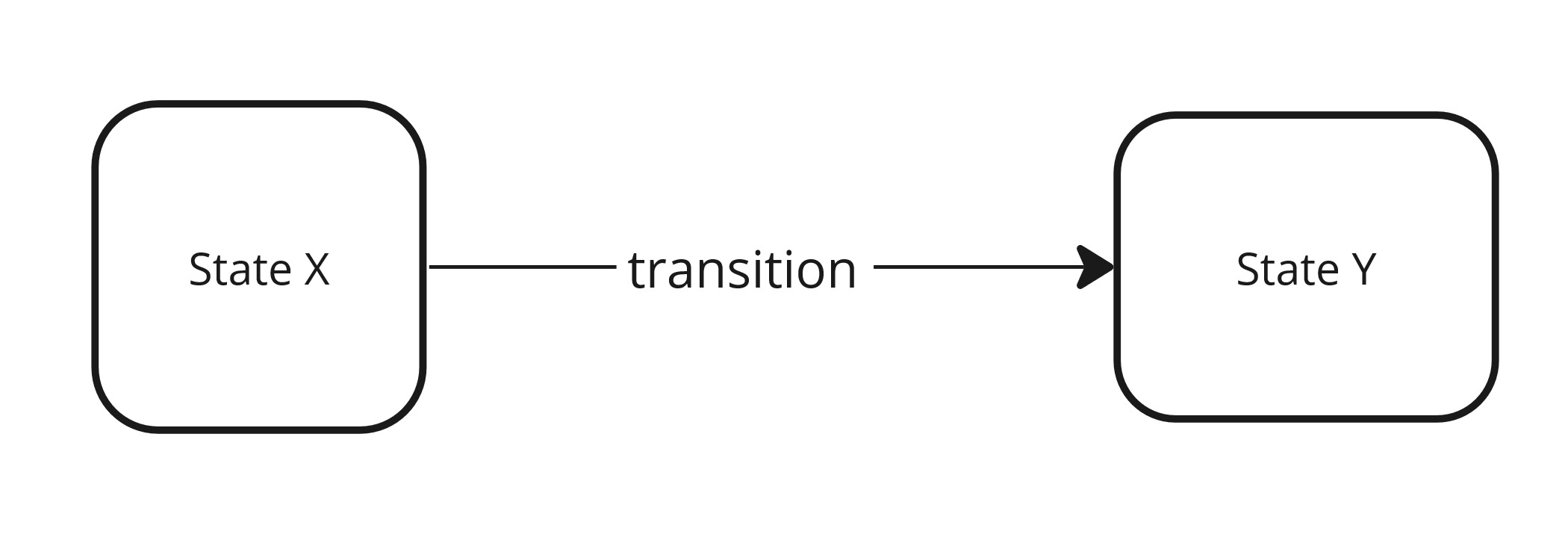
System - states & transitions.
Controllability is the ease of transition from one state to another, that is, the ease of invoking transitions. According to the state machine concept, transitions are made under the influence of events and the source of events are intentions (commands). That is, successfully invoking the command in state X causes a state change (event) - that is, the transition of the system to state Y.
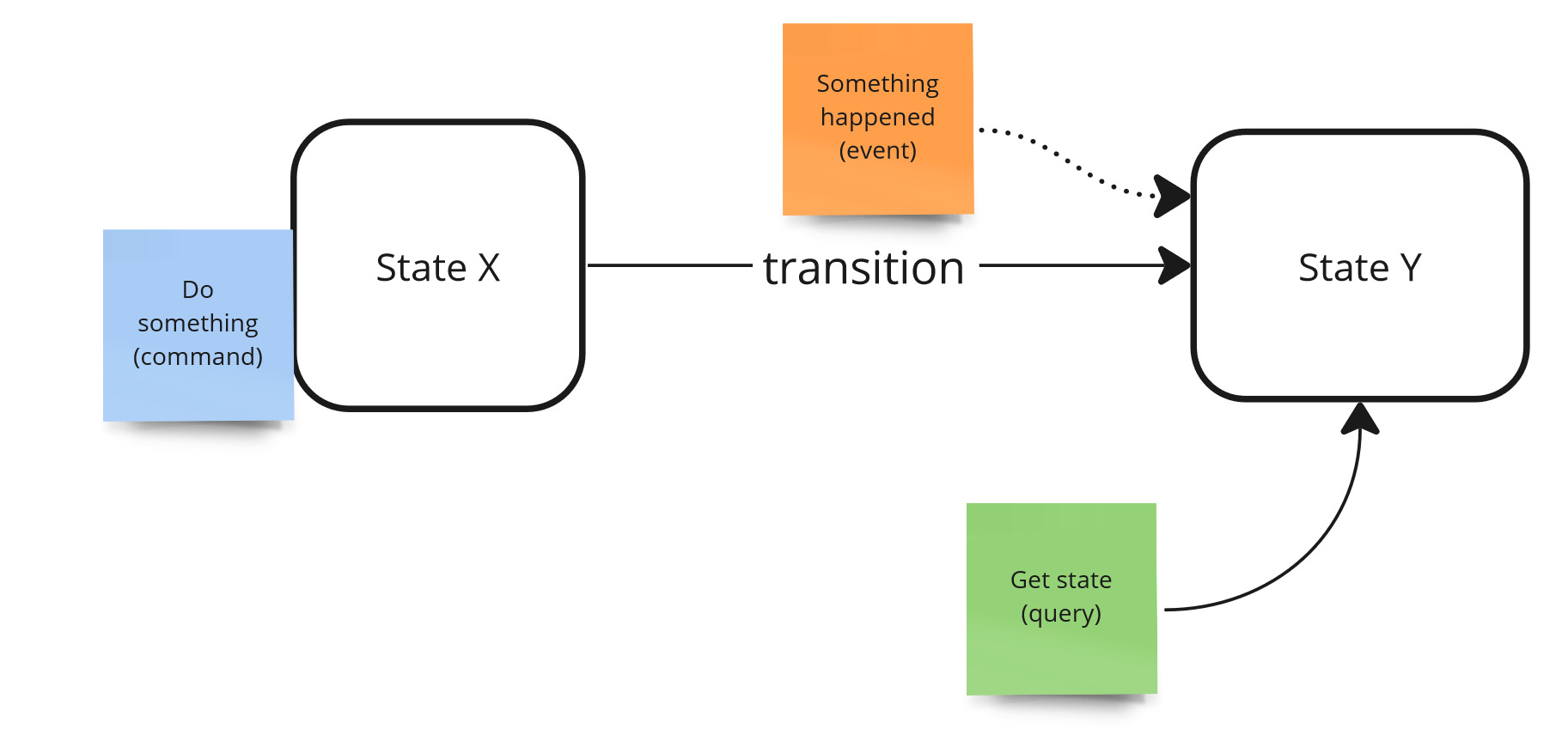
System states - commands & events.
An important question we must ask ourselves is who is the initiator of a given action and how does he do it. It can be a human and then he will trigger the action through the some kind of interface like GUI or CLI. It can also be a automated mechanism that will trigger this action based on some other events.
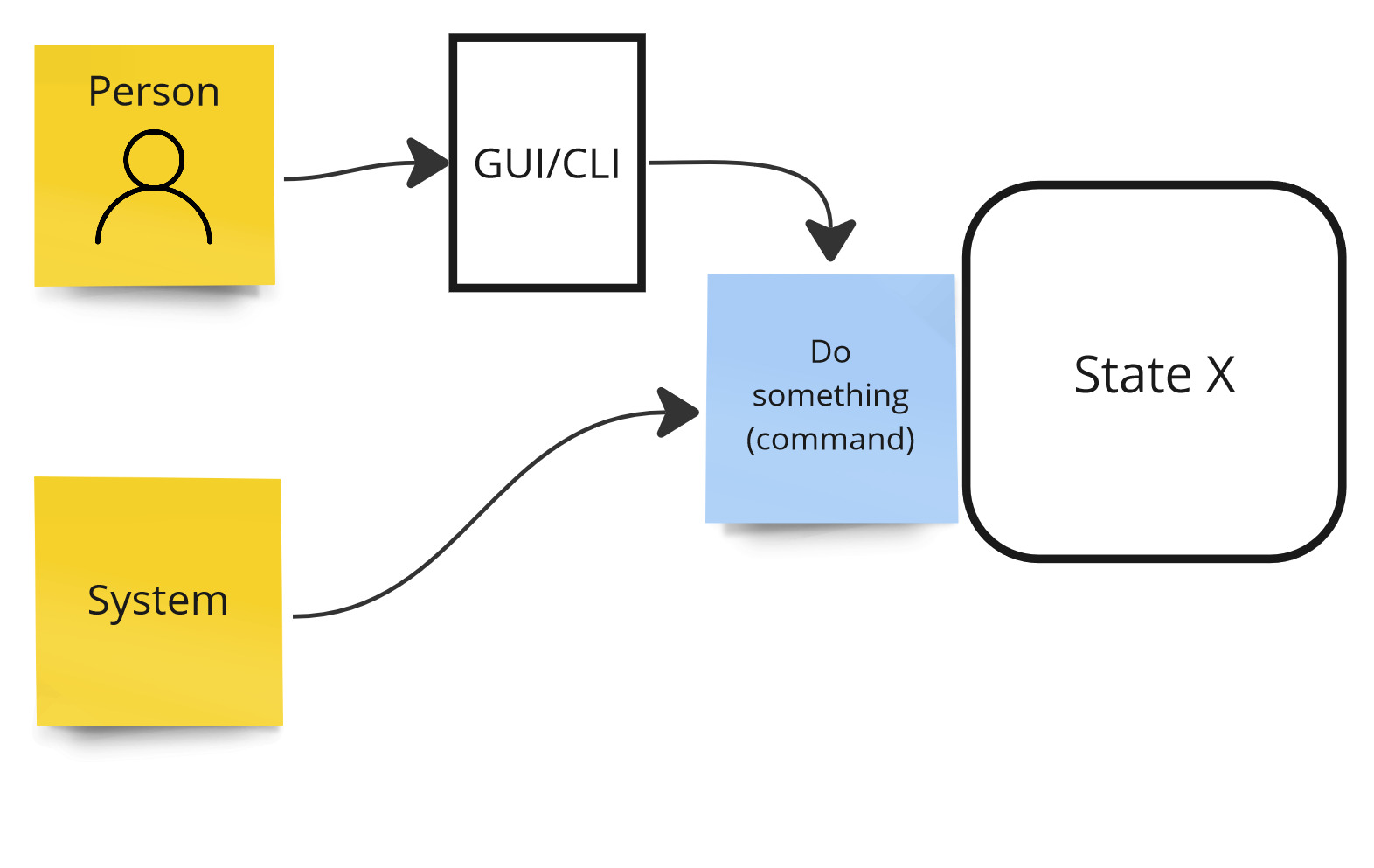
Controllability - actors, initiators of transitions.
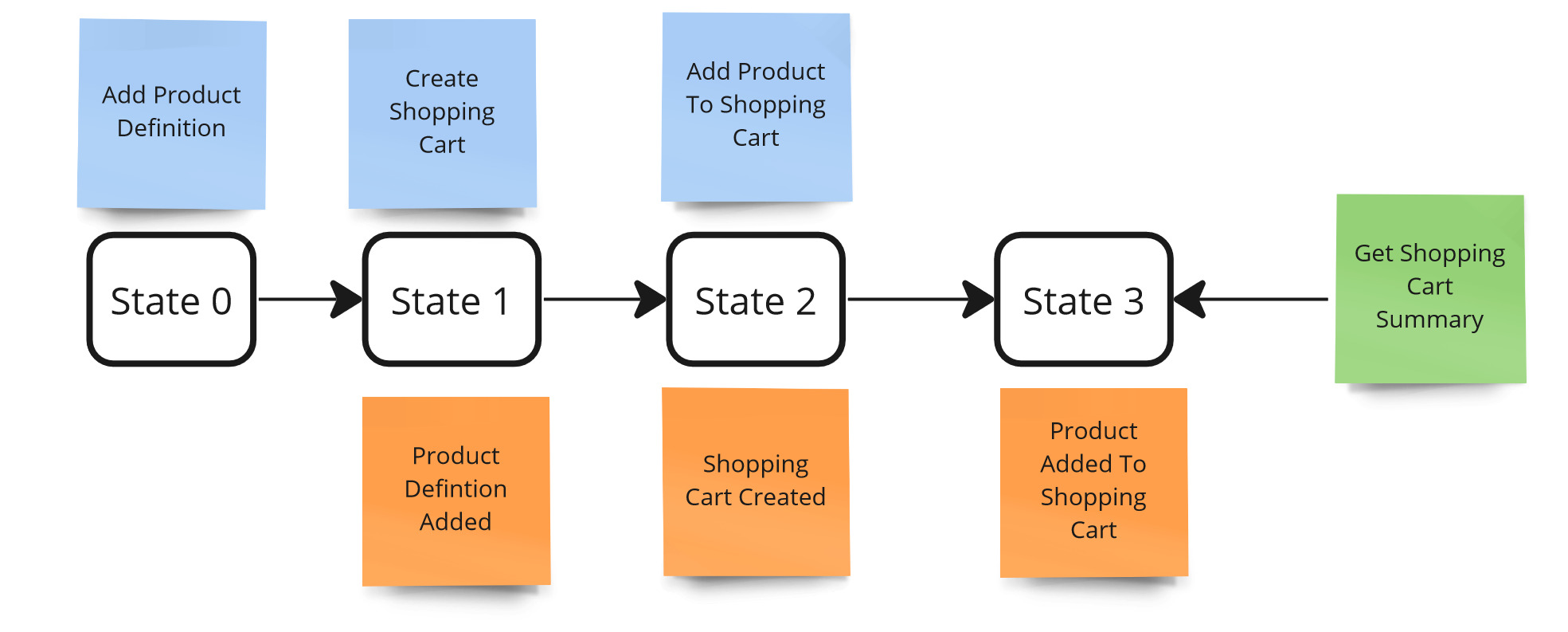
Let’s see it on an example. Suppose we have a shopping cart and we can add products to it. Our system is in state 0 - no previous actions. To add products to the cart:
- Create a product definition
- Create a shopping cart
- Add products to the Cart
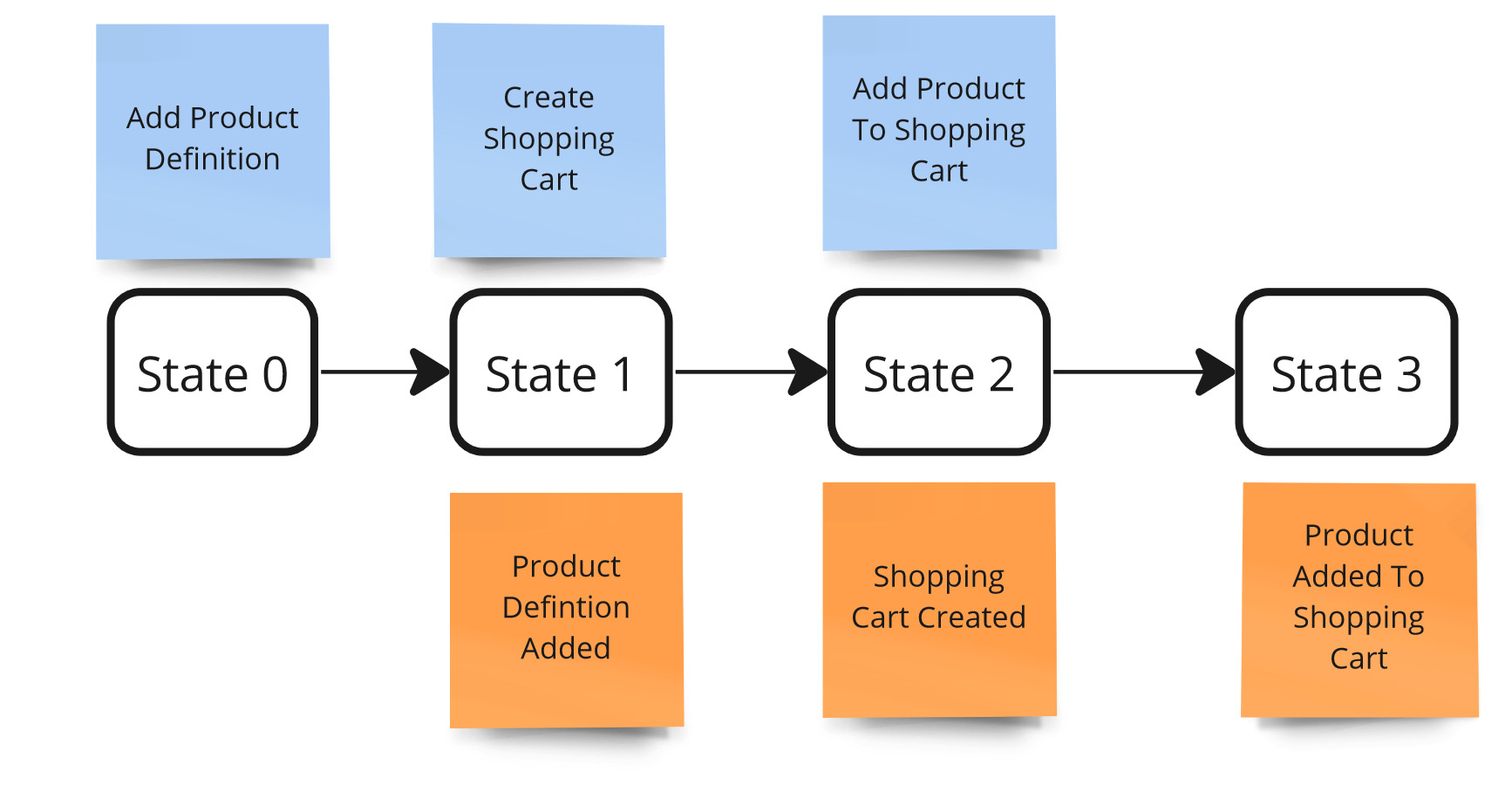
Controllability - example.
According to what has been presented, controllability is the ease of executing commands on our system. The easier it is for us to do it, the better.
Let’s assume that adding a product definition happens in our system through some graphical interface. At this point we can say that we are able to control it manually. In addition, our graphical interface uses the REST service for this, so we are also able to use it and automate this step of the process.
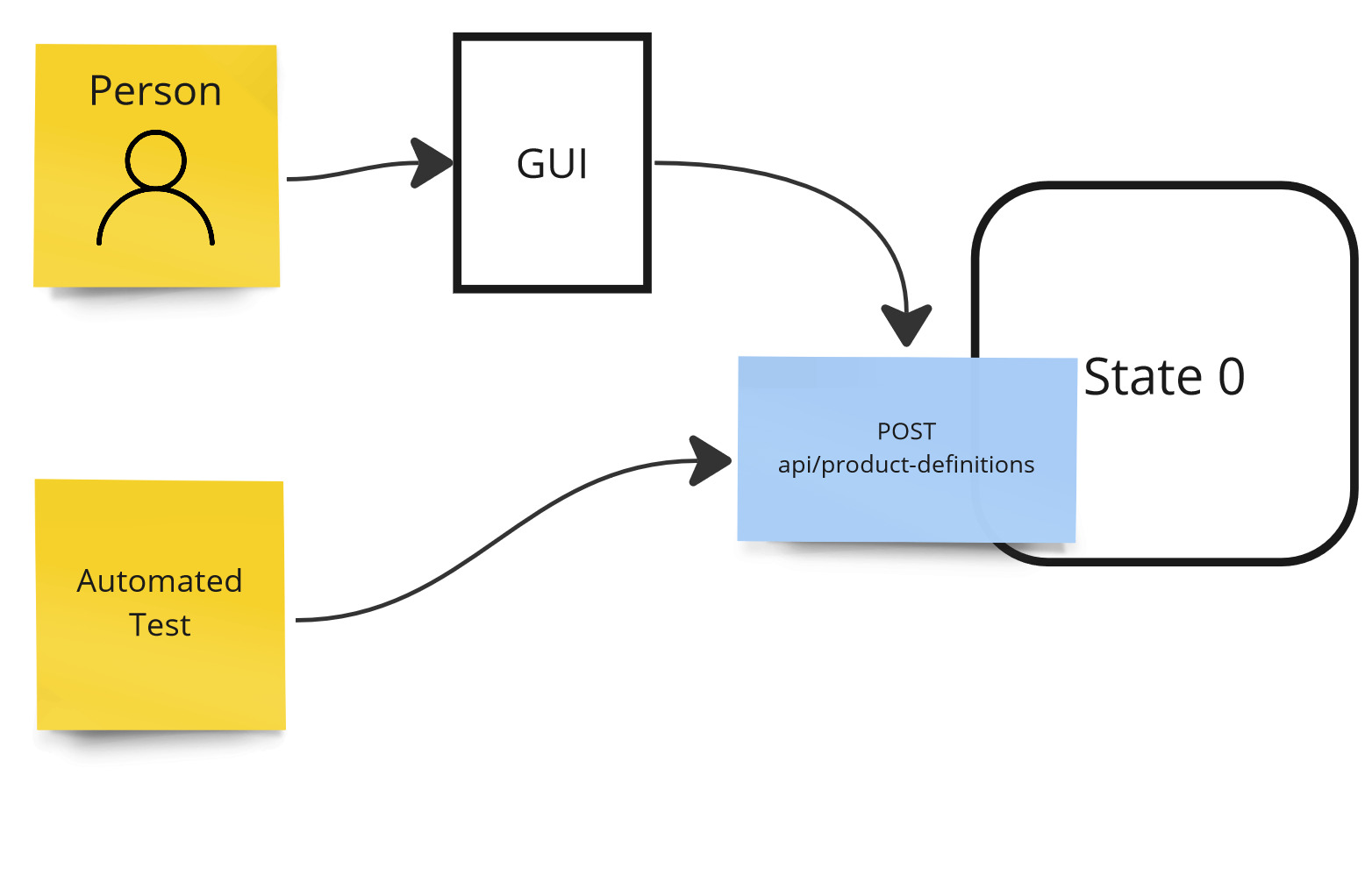
Controllability example - high degree of control.
However, let’s consider a different scenario. This time, defining products takes place in another system that is beyond our control (e.g. in the product catalog service). Our system learns about new products from events and adds them. In this case, you cannot add a new product via the graphical interface, nor can you use any service for it for automation purposes. You can’t control your system state.
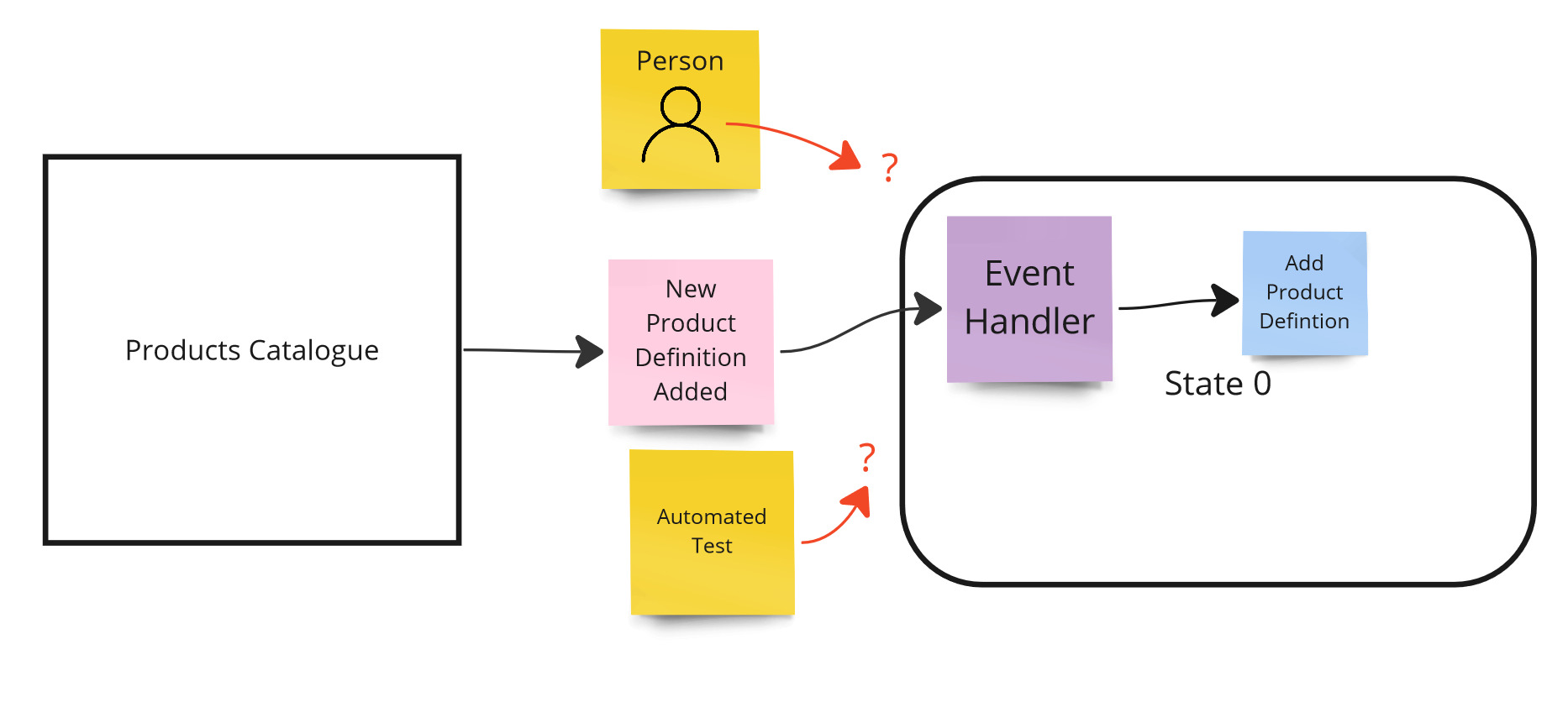
Controllability example - low degree of control.
We can draw two conclusions from this. The first is that decomposing functionality reduces our controllability at the level of the entire system. In other words, if we decompose something, it becomes harder to test it in its entirety. For example, to test the entire process manually, you would first have to create a product definition in the catalog and wait for our system to process the event. This is already a system test.
On the other hand, it is easier to understand smaller components than larger ones. Therefore, considering a single part of the system such as a service or module, the ease of understanding (more on that later) increases and the testability of that specific part also increases.
But what about controlling our part of the system? We can increase control using Subcutaneous Test. This test runs a layer lower than the HTTP layer, at the application layer (use case). As a result, we always have access to the API of our module, so we can automatically control the state of our system.
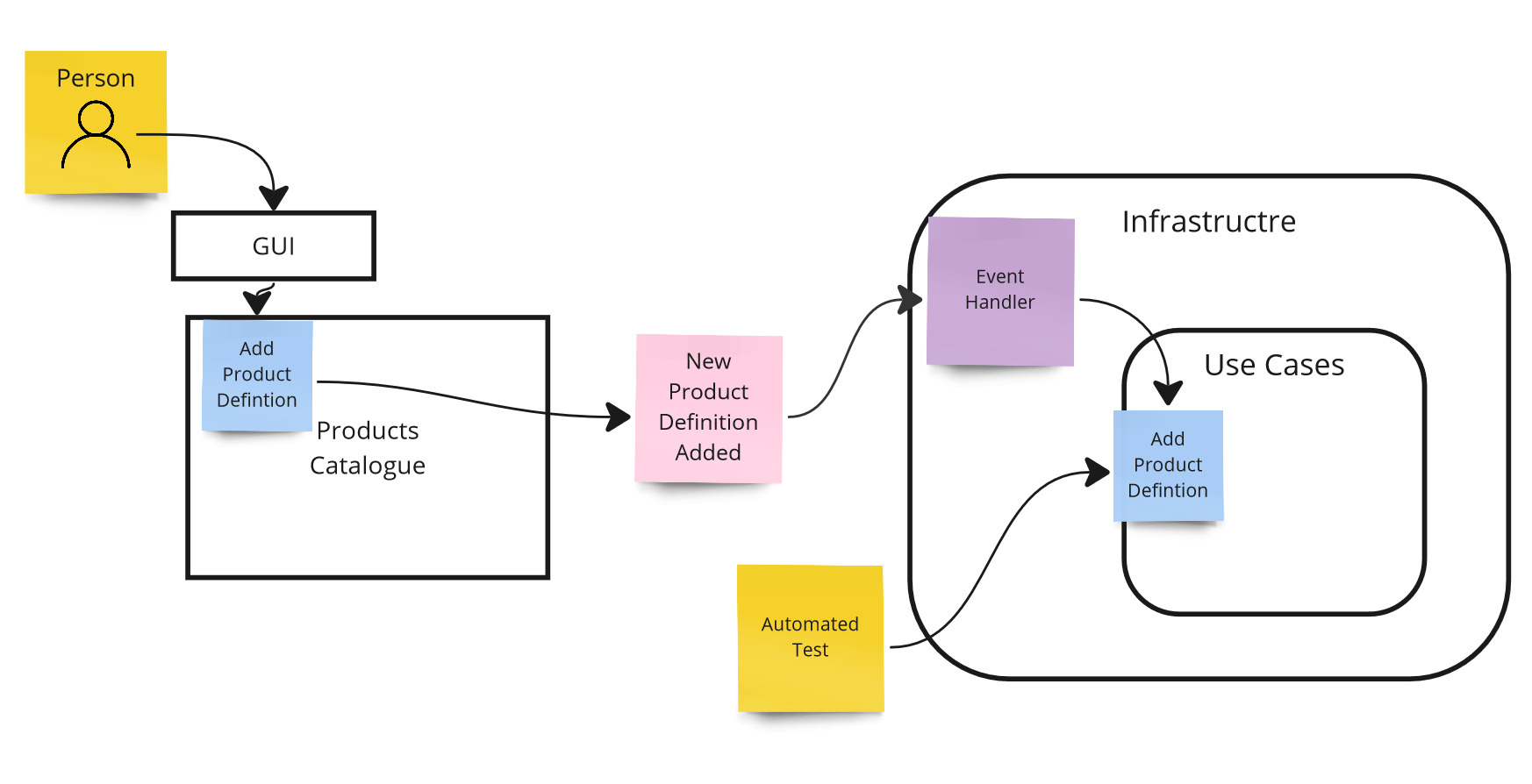
Controllability example - automated test via use case layer.
Thus, our test could look like this:
public async Test()
{
// Given
var productId = await SalesModule.ExecuteCommand(new AddProductDefinitonCommand(...));
var shoppingCartId = await SalesModule.ExecuteCommand(new CreateShoppingCartCommand(...));
await SalesModule.ExecuteCommand(new AddProductToShoppingCartCommand(shoppingCartId, productId, ...));
}Observability
The second factor of testability is observability. Observability defines how easy it is for us to observe changes in the system, in other words, how easy it is for us to check the state of our system after a change has been made.
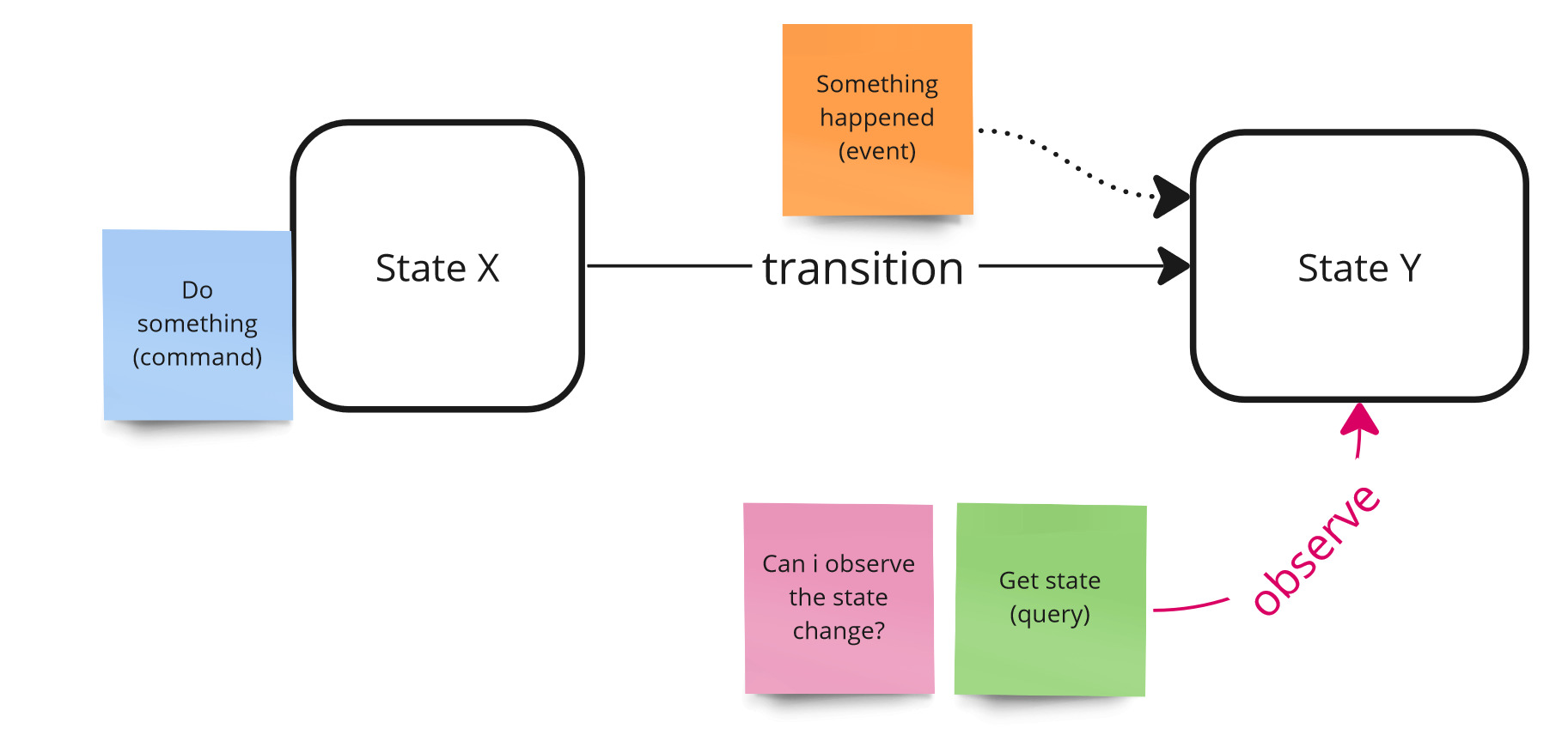
Observability.
How do we check the state of our system? By asking about it, i.e. by making queries. Continuing the example, we’ll want to ask about the status of our cart.
Observability - example.
Again, we have to ask ourselves: who is the initiator of the query? If we want to test it manually, we need to have an interface ready to show us a cart summary. If we do not have such an interface (e.g., it has not yet been implemented), then we are not able to observe the state change. The only thing we can do is to check the data in the database, but then these are white-box tests and do not guarantee the correct operation of the system.
On the other hand, there may not be a suitable use case to return this data. If it is not there, how do we check the state change automatically? The answer is simple - we need to implement such a use case only for testing purpose, even though it will not be used in the production code at the moment. Many people are against writing functionality only for tests, but let’s remember - tests are production code, and it is one of the clients of our system. To be honest, automated test should be the first client of your system. In addition, sooner or later, such a use case will probably be needed for the purposes of displaying data on the interface or some internal processing, so we will be able to use it.
This allows our automated test to look like this:
public async Test()
{
// Given
var productId = await SalesModule.ExecuteCommand(new AddProductDefiniton(...));
var shoppingCartId = await SalesModule.ExecuteCommand(new CreateShoppingCart(...));
await SalesModule.ExecuteCommand(new AddProductToShoppingCart(shoppingCartId, productId, ...));
// When
var shoppingCartSummary = await SalesModule.ExecuteQuery(new GetShoppingCartSummary(shoppingCartId));
// Then
shoppingCartSummary.Should()...
}Unfortunately, things get more complicated when we modify a state we don’t control during processing. A classic example here is sending an e-mail or calling some external system that we cannot query about the state.
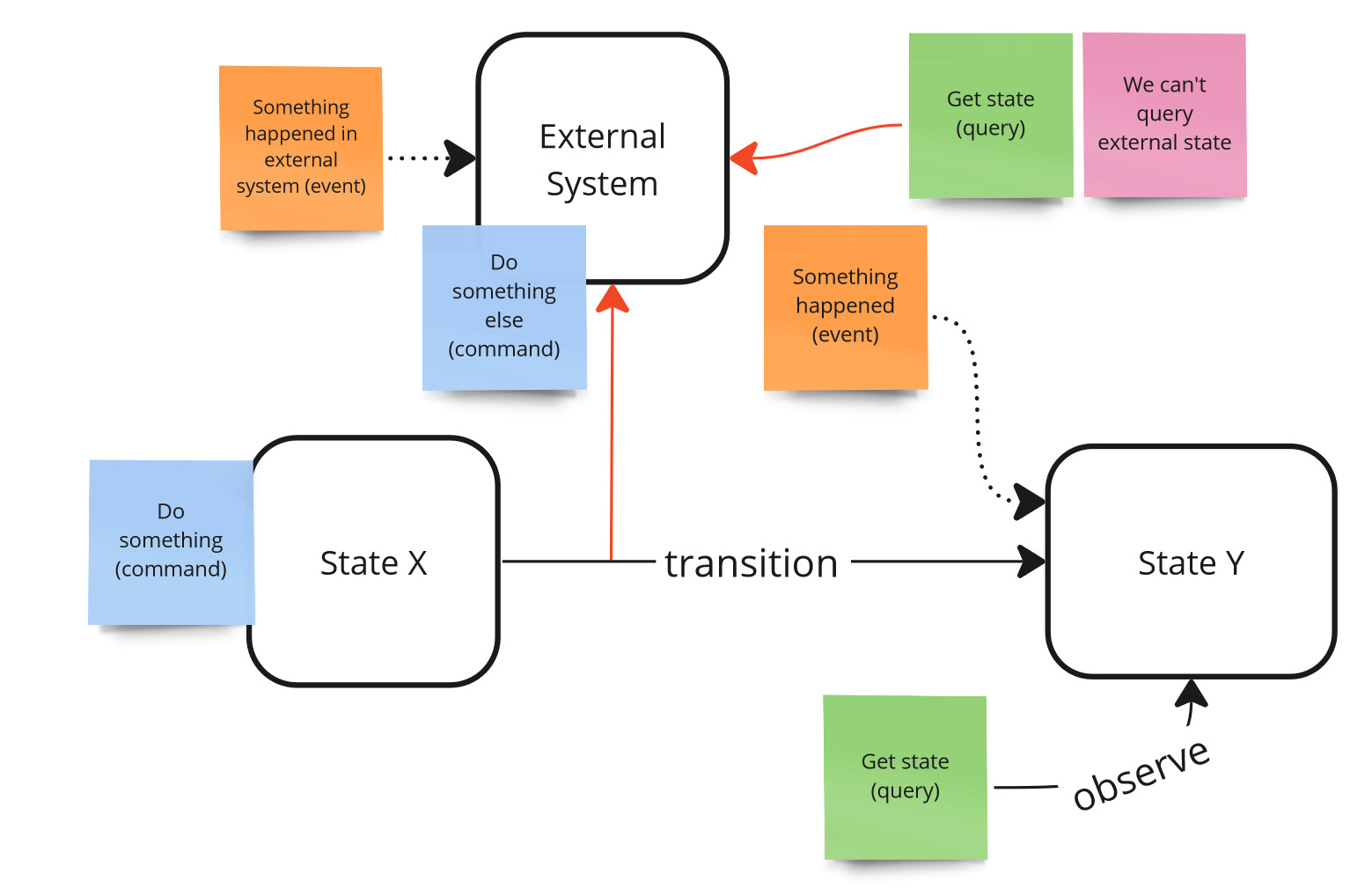
Observability - external, uncontrollable system.
In order to test such a use case manually, we must have access to the external system interface (assuming it exists and such a view is available).
If we wanted to automate it, the external system would have to provide some service that returns this data. The solution to this problem is interaction testing, which are less stable than state-based testing but often the only right choice. To carry out such a test, you need to create a mock of such a service and verify that the given mock has been invoked with the appropriate arguments.
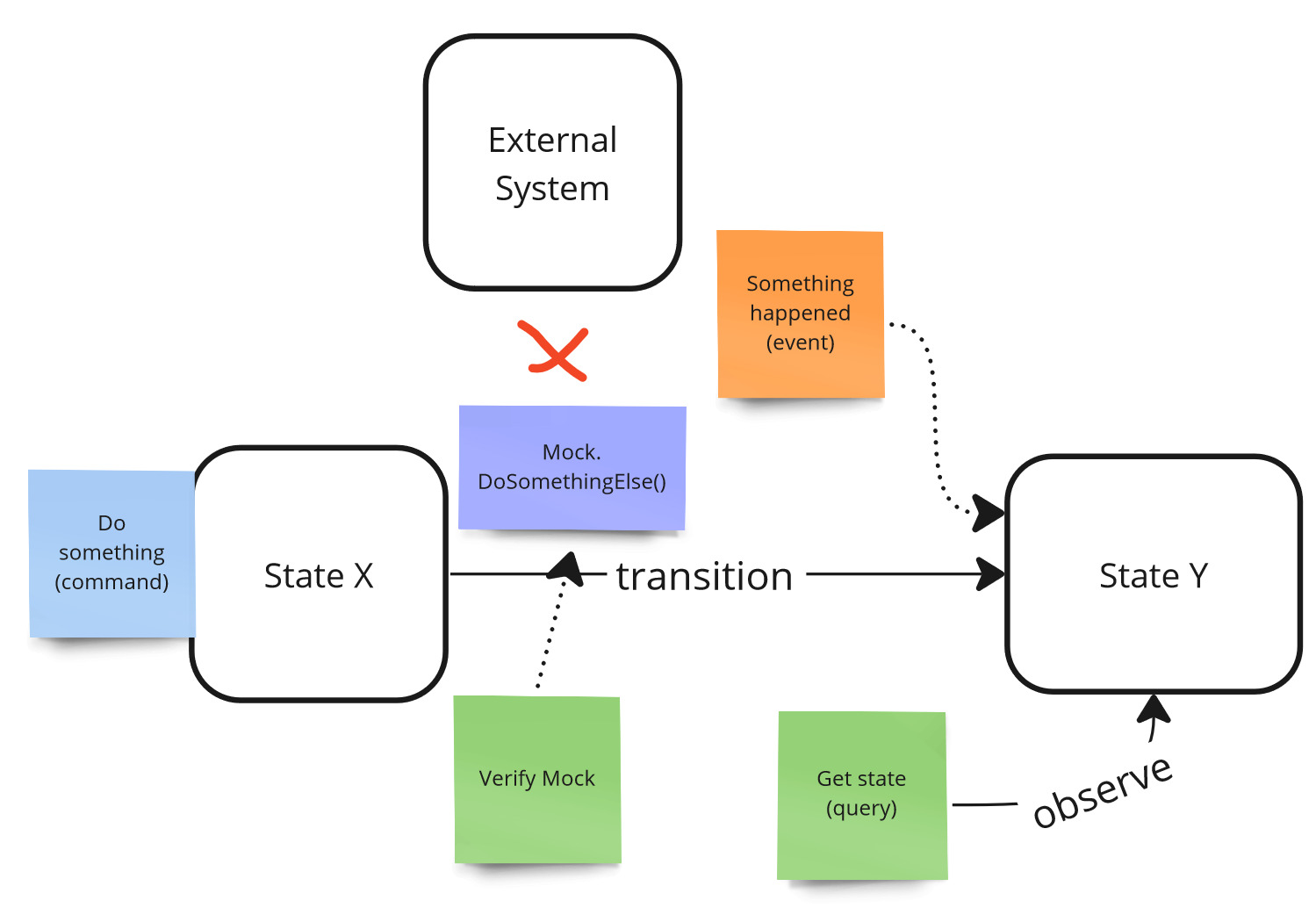
Observability - external system, mocking, interaction testing.
In this way, our mock test could look like this:
public async Test()
{
// Given
var fakeSenderMock = new FakeSenderMock();
SalesModule = new SalesModule(fakeSenderMock);
var productId = await SalesModule.ExecuteCommand(new AddProductDefiniton(...));
var shoppingCartId = await SalesModule.ExecuteCommand(new CreateShoppingCart(...));
// When
await SalesModule.ExecuteCommand(new AddProductToShoppingCart(shoppingCartId, productId, ...));
// Then
fakeSenderMock.WasExecutedWithArgs(...);
}
In this way, we isolated ourselves from the external system, which is another factor affecting testability.
Isolateability
Isolateability refers to the extent to which we can isolate ourselves from other collaborators during testing.
Not being able to isolate ourselves from external collaborators can lead to two issues. First, if we rely on an external system to provide us some data, the response we receive may be non-deterministic. Determinism is a crucial aspect of any type of test. Without it, the test may be considered unreliable and even decrease our confidence in the system.
Secondly, if we instruct an external system to perform an action, there is a risk that this action may result in irreversible changes (for example, sending an email to a client on production).
In some cases, it may be challenging or even impossible to have the external system running locally, which is a separate topic altogether.
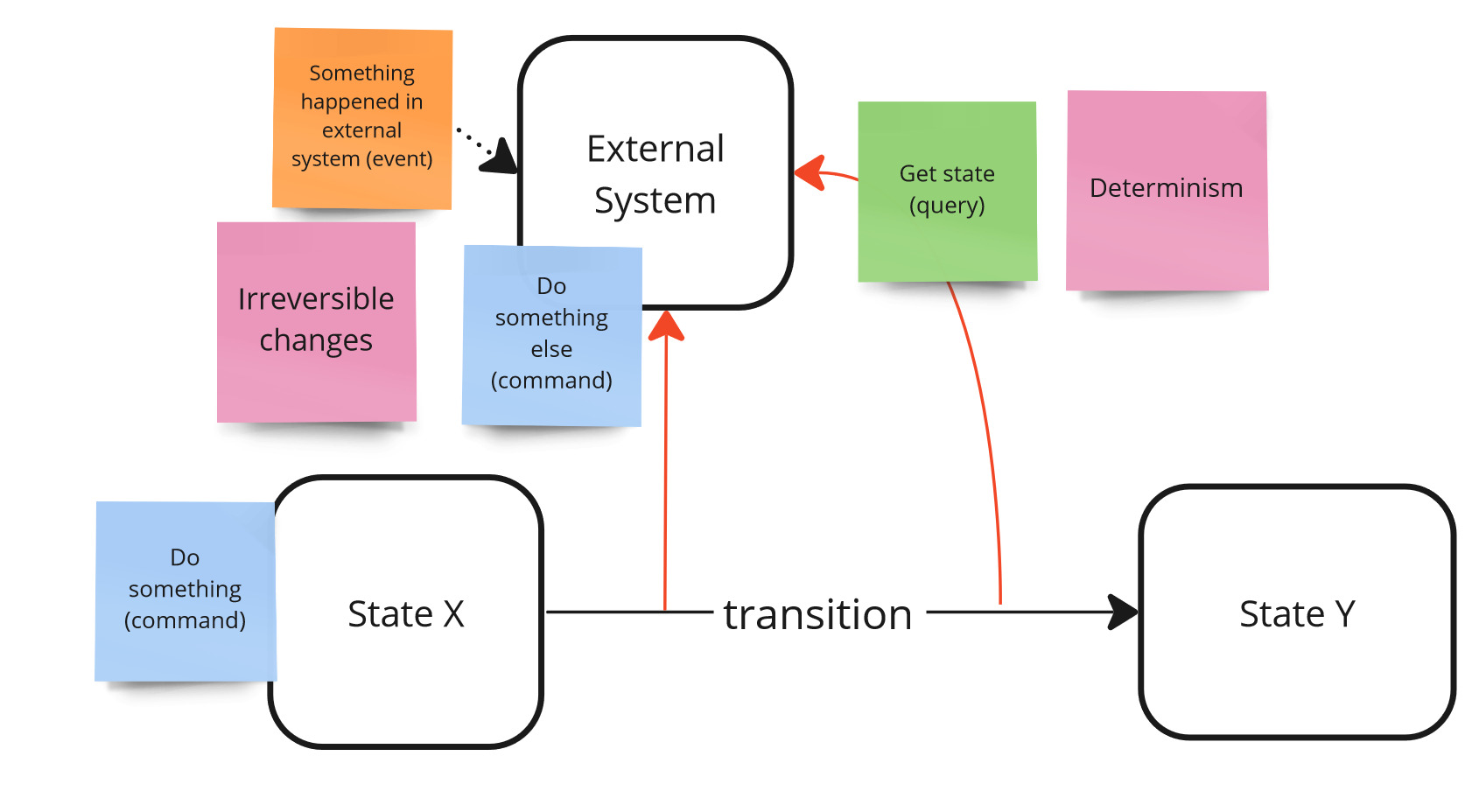
Isolateability problem.
To solve this, stubs (for queries) and interaction testing via mocks (for commands) are most often used - as it was shown above when discussing observability.
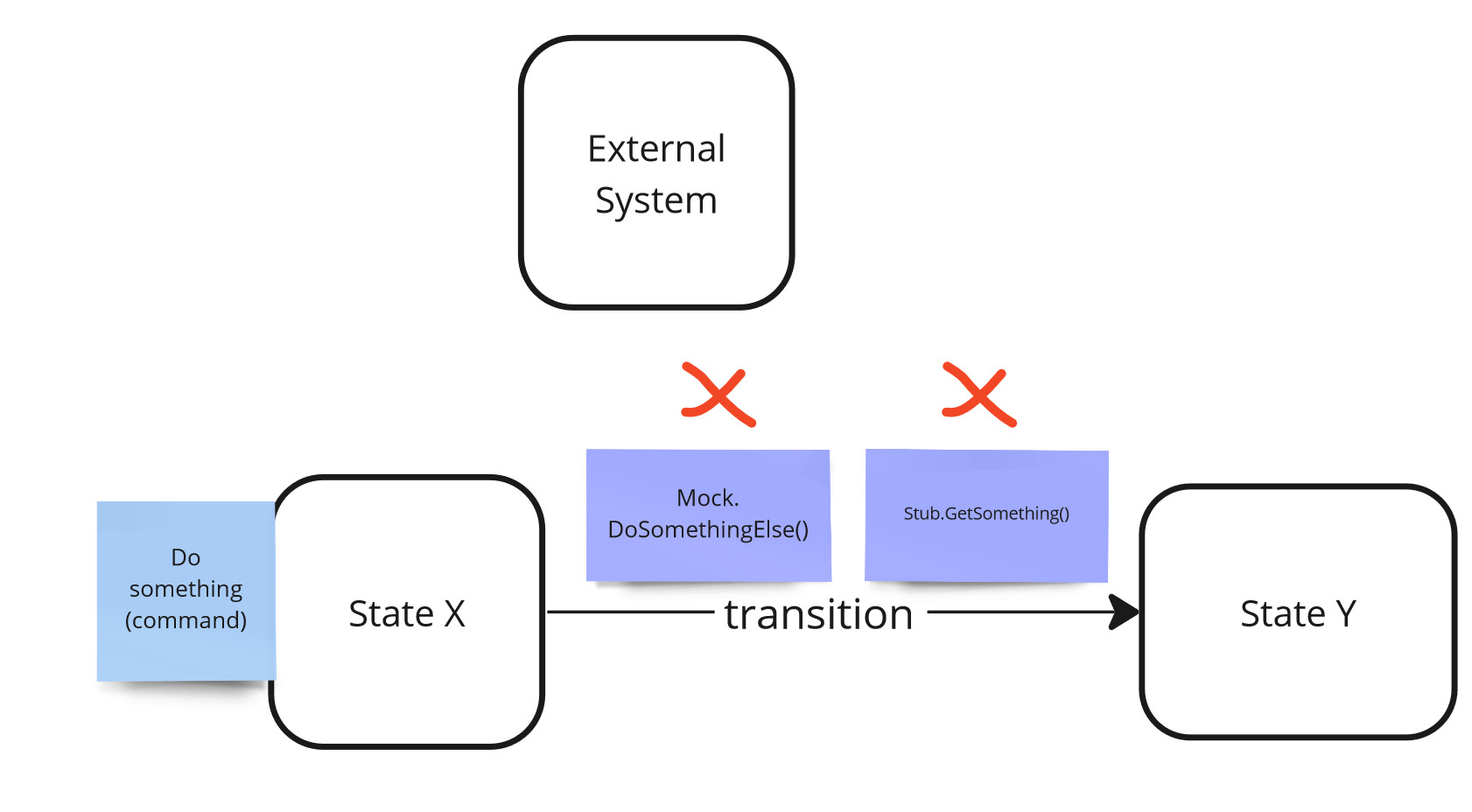
Isolateability - mocks and stubs
Automatability
Another important factor affecting testability is the level to which we are able to automate our tests - automatability.
As it was mentioned earlier, we need to both control the state of our system and observe its changes in an automated way. If we are unable to do all steps in automated way, we are not able to automate such a scenario.
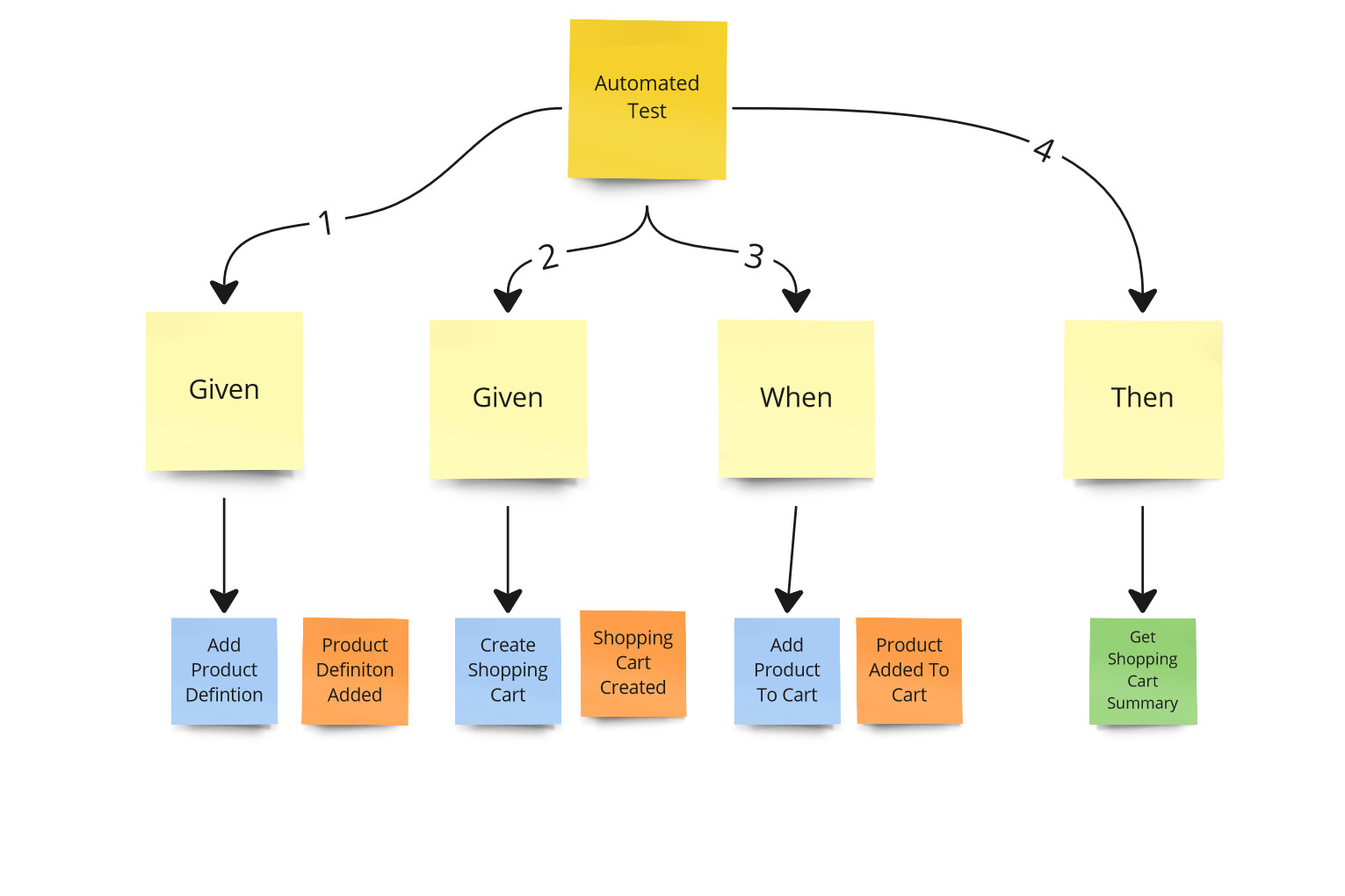
Automatability
The ability to automate is one thing, but the way and quality of automation are other factors that can affect testability. Tests can be fast or slow, give more or less confidence, and easy or difficult to maintain, and all of these aspects can impact testability. We will discuss these factors in more detail when we discuss testing strategy in the next post.
Understandability
Testing, as defined by the common definition, involves the verification and validation of compliance with requirements. Therefore, testing doesn’t make sense if we don’t understand the business and system requirements. To perform a given test correctly, we need to comprehend all the steps of a test scenario, whether we execute it manually or write an automated test.
Writing and executing tests helps us understand requirements from a different perspective than when implementing a particular functionality. This way, we have double verification. Furthermore, since some test scenarios are written by other people, such as a QA engineer, we have an additional check that ensures that everyone comprehends the requirement in the same way.
Understandability - do I understand it?
Performing and writing tests gives us a quick feedback loop - we can immediately verify whether our mental model of requirements is correct. Thanks to this, we are able to learn the domain faster, which is another advantage of testing.
It also works the other way - we can reverse engineer the requirements from the tests. We can understand what steps are required in a given process and what data is processed. The better the tests, the better the understanding; the easier it is to write tests.
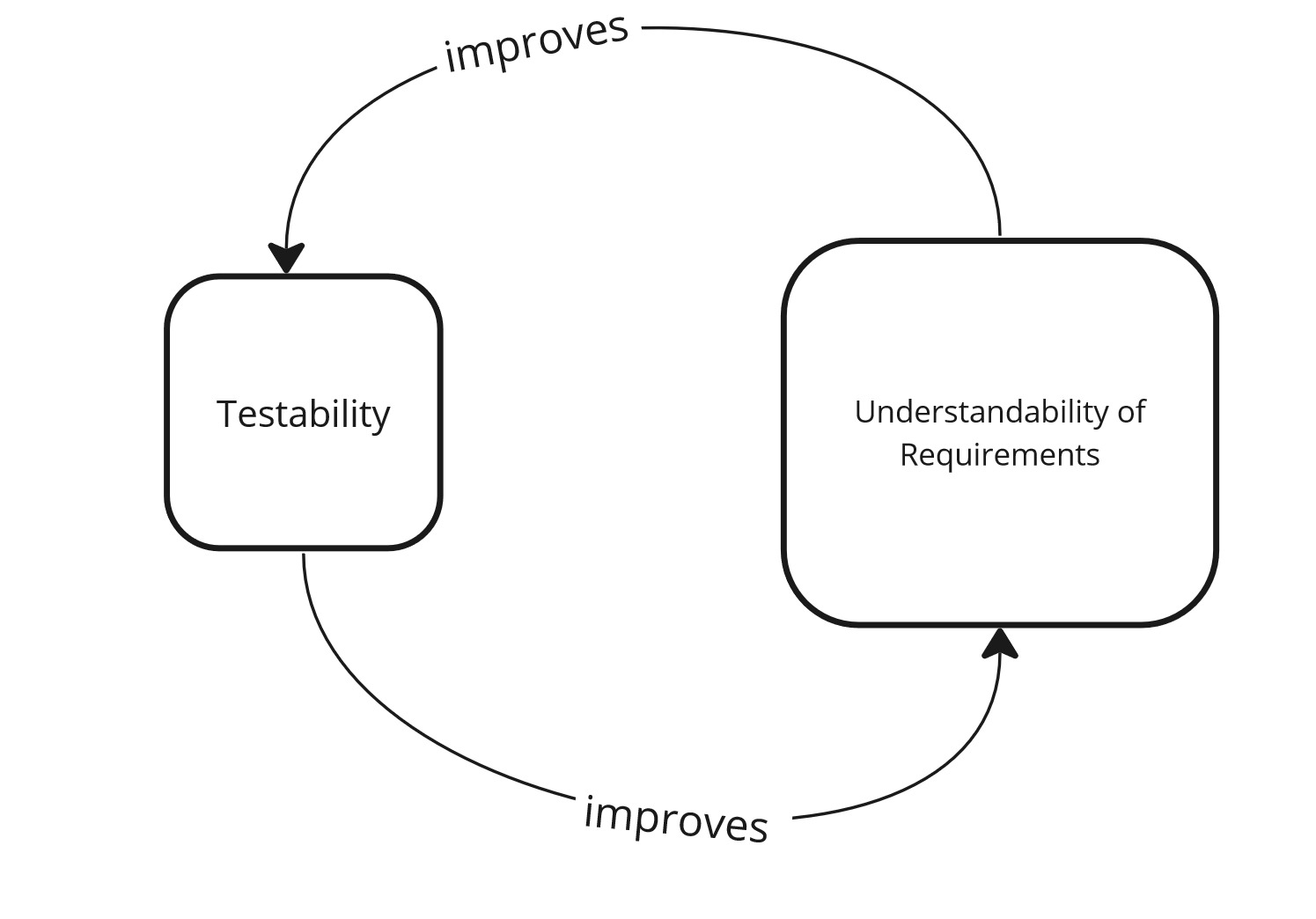
Understandability - feedback loop.
Summary
Below are the key takeaways:
- Testability tells us how easily we can test our system
- Testable architecture is an architecture that supports testing and prioritizes them
- The main attributes of testability are controllability, observability, isolateability, automatability, and understandability
- Controllability is a measure of how much we are in control of our system - whether and how we are to pass from one state to another
- Observability defines how easy it is for us to observe changes in the system
- Isolateability is the level to which we are able to isolate ourselves from other collaborators
- Automatability is the level to which we are able to automate our tests
- Understandability is the level at which we understand what we test
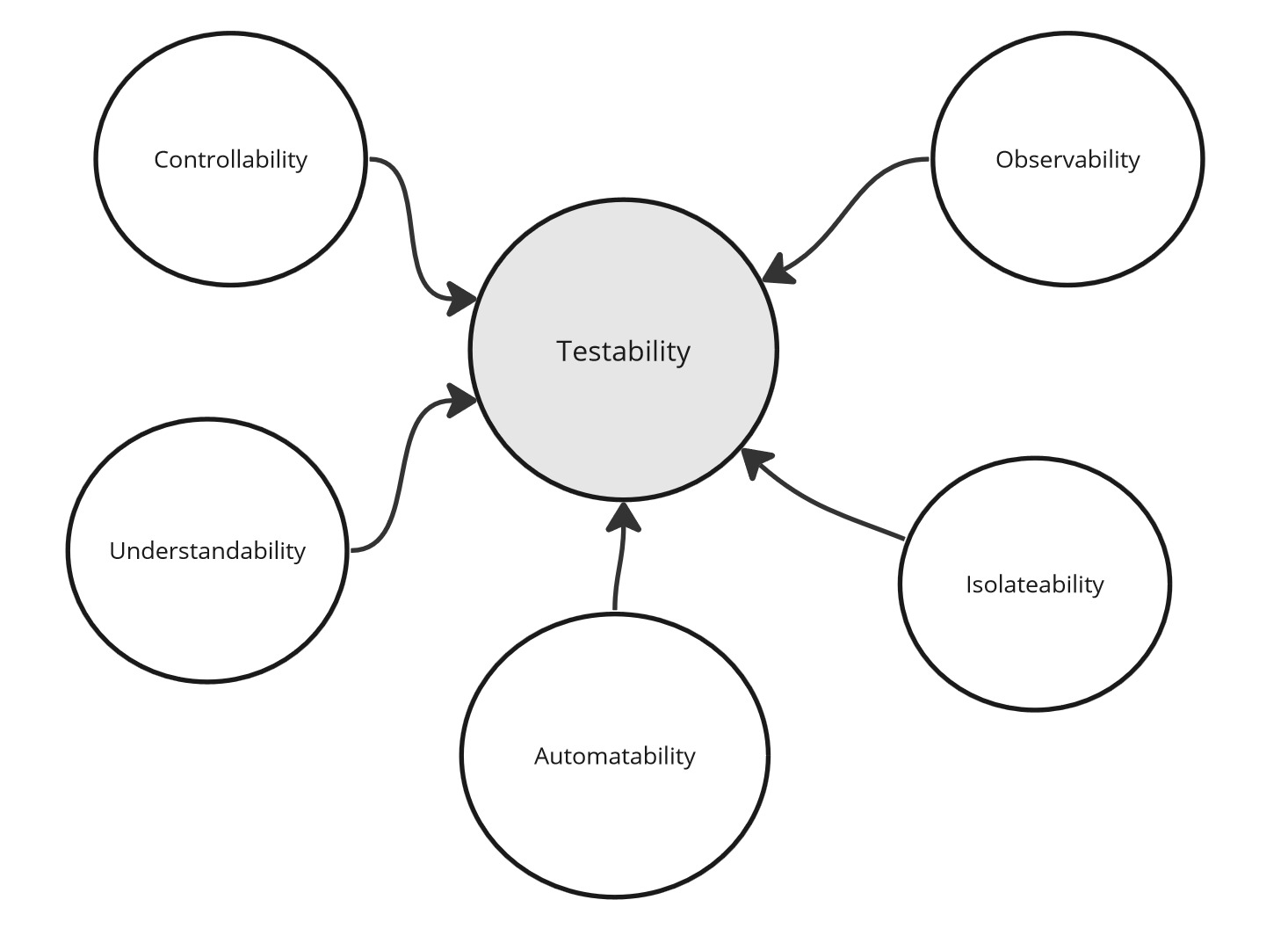
Testability - Summary.
More in series
This post is part of the Automated Tests series:
Comments
Related posts See all blog posts
